


检测到是安卓设备,电脑版软件不适合移动端
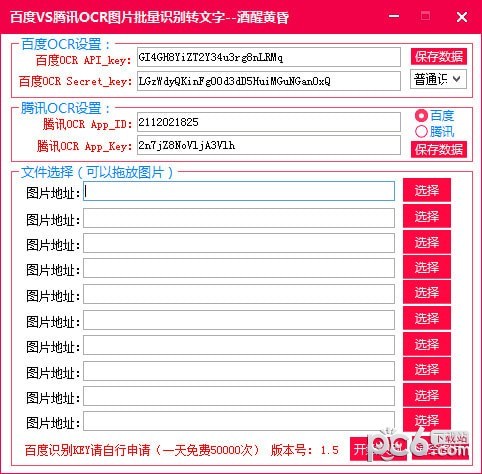
百度搜索VS腾讯官方OCR图片大批量识别转文字是一款图片识别文字软件,软件根据连接百度与腾讯官方ocr识别插口,能够完成完全免费文本识别作用,可精确的对文本字体样式开展识别和文章段落分割。

OCR软件主要是由下边好多个一部分构成。
图象键入、预备处理:
图象键入:针对不一样的图像文件格式,拥有 不一样的储存文件格式,不一样的压缩方式,现阶段有OpenCV,CxImage等开放源代码项目 。预备处理:关键包含二值化,噪音除去,歪斜效准等
二值化:
对监控摄像头拍攝的图片,大部分是数字图像,数字图像所含信息量极大,针对图片的內容,我们可以简易的分成市场前景与情况,为了更好地让电子计算机迅速的,更强的识别文本,大家必须先向彩色图开展解决,使图片只市场前景信息与情况信息,能够简易的界定市场前景信息为灰黑色,情况信息为白,这就是二值化图了。
噪音除去:
针对不一样的文本文档,大家对噪声的定义能够不一样,依据噪音的特点开展去噪,就称为噪音除去
歪斜较正:
因为一般客户,在拍照文本文档时,都较为随便,因而拍照出去的图片难以避免的造成歪斜,这就必须文本识别软件开展较正。
版面剖析:
将文本文档图片分文章段落,支行的全过程就称为版面剖析,因为具体文本文档的多元性,多元性,因而,现阶段都还没一个固定不动的,最优化的激光切割实体模型。
标识符激光切割:
因为拍照标准的限定,常常导致标识符黏连,断笔,因而巨大限定了识别系统软件的特性,这就必须文本识别软件有标识符激光切割作用。
标识符识别:
这一科学研究,早已是很早以前的事儿了,较为早有模板匹配,之后以svm算法为主导,因为文本的偏移,字的笔画的大小,断笔,黏连,转动等要素的危害,巨大危害特点的获取的难度系数。
版面修复:
大家期待识别后的文本,依然像原文本文档图片那般排序着,文章段落不会改变,部位不会改变,次序不会改变,的輸出到word文本文档,pdf文本文档等,这一全过程就称为版面修复。
后处理工艺、审校:
依据特殊的語言前后文的关联,对识别結果开展较正,便是后处理工艺。
1、打开浏览器输入网址:https://cloud.baidu.com/ 后申请办理一个账户(申请办理是完全免费的不要钱)
2、点一下创建运用 (创建运用 也是完全免费的 )
3、运用早已创建好啦,里边就会有 api_key 和Secret_Key 运用能够创建无数懒得理你创建是多少都能够,每一个创建的密匙都不一样
4、创建运用了,看一下是不是已启用了文本识别作用
5、之上都实际操作结束就取出你申请办理的 KEY 就可以应用了!
【版本更新】
1.调整某些电脑上识别只显示信息识别一张图的难题。
2.软件终止升级。

软件信息
程序写入外部存储
读取设备外部存储空间的文件
获取额外的位置信息提供程序命令
访问SD卡文件系统
访问SD卡文件系统
查看WLAN连接
完全的网络访问权限
连接WLAN网络和断开连接
修改系统设置
查看网络连接
我们严格遵守法律法规,遵循以下隐私保护原则,为您提供更加安全、可靠的服务:
1、安全可靠:
2、自主选择:
3、保护通信秘密:
4、合理必要:
5、清晰透明:
6、将隐私保护融入产品设计:
本《隐私政策》主要向您说明:
希望您仔细阅读《隐私政策》
 最新软件
最新软件
 相关合集 更多
相关合集 更多
 相关教程
相关教程
 热搜标签
热搜标签
 网友评论
网友评论
 添加表情
添加表情 
举报反馈

 色情版权反动暴力软件失效其他原因
色情版权反动暴力软件失效其他原因
 官方
官方  纠错
纠错 




































 监狱风云
监狱风云 监狱混战
监狱混战 监狱逃生
监狱逃生 监狱生活
监狱生活 高架监狱
高架监狱 小小监狱
小小监狱 像素监狱
像素监狱 越狱监狱
越狱监狱
 开罗拉面店汉化版
开罗拉面店汉化版 游戏鱼游戏盒子
游戏鱼游戏盒子 开罗网球俱乐部汉化版
开罗网球俱乐部汉化版 开罗拉面店电脑版
开罗拉面店电脑版 开罗百货商店日记2
开罗百货商店日记2 开罗网球俱乐部电脑版
开罗网球俱乐部电脑版 游戏鲸鱼游戏平台
游戏鲸鱼游戏平台 幻影游戏(游戏多开)
幻影游戏(游戏多开)
