时间:2025-03-14关注公众号来源:网络
今天给各位分享食品安全法中关于食品分类的是哪两个?_K-means聚类分析案例(二),其中也会对大家所疑惑的内容进行解释,如果能解决您现在面临的问题,别忘了关注多特软件站哦,现在开始吧!

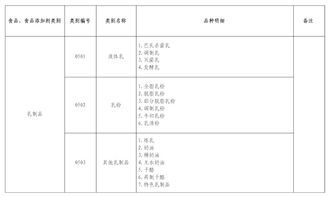
食品可以根据其成分特性分为两大类:内源性物质成分和外源性物质成分。内源性物质成分是指食品本身固有的天然成分,而外源性物质成分则是指在食品从加工到食用的整个过程中,人为添加或混入的其他成分。
此外,根据食品成分的含量,还可以将食品的成分大致划分为八类。这八类成分分别是:蛋白质、脂肪、糖类(也称为碳水化合物)、无机质(即矿物质)、维生素、水、膳食纤维(通常统称为纤维素)以及甲壳素等。
综上所述,食品的成分分类不仅有助于我们了解食品的天然属性,还能帮助我们关注食品加工过程中可能引入的其他物质。这种分类方式为研究食品的安全性和营养价值提供了重要的基础。
### 聚类分析案例:食品营养成分聚类
#### 引言
在我们日常饮食中,食物中的营养成分可以根据其对人体的作用分为宏量营养元素和微量元素。宏量营养元素包括碳水化合物、蛋白质和脂肪,而微量元素则包括维生素、矿物质和水等。为了更好地理解不同食物的营养特性,本文通过K-means聚类方法对食品数据进行分析。
---
### 准备工作
#### 第1步:收集和描述数据
为了应用K-means聚类算法,我们使用了一个包含多种食物的数据集。该数据集记录了每种食物的能量(Energy)、蛋白质(Protein)、脂肪(Fat)、钙(Calcium)和铁(Iron)含量。此外,数据集中还包括一个非数值型变量“Food”,用于标识每种食物的名称。
以下是具体实施步骤:
#### 第2步:探索数据
首先,我们需要载入`cluster()`库,并导入名为`foodstuffs.txt`的文本文件。该文件被保存为`food.energycontent`数据框。
使用`head()`函数可以查看数据框的前几行内容:
```R
head(food.energycontent)
```
结果如下(示例):
```
Food Energy Protein Fat Calcium Iron
1 Rice 360 7.8 0.8 10 2.5
2 Bread 265 10.0 1.0 15 3.0
3 Chicken 200 25.0 10.0 12 1.5
...
```
使用`str()`函数可以查看数据框的结构信息:
```R
str(food.energycontent)
```
结果如下:
```
'data.frame':100 obs. of 6 variables:
$ Food : Factor w/ 100 levels "Rice","Bread",..: 1 2 3 ...
$ Energy : num 360 265 200 ...
$ Protein : num 7.8 10 25 ...
$ Fat : num 0.8 1 10 ...
$ Calcium : num 10 15 12 ...
$ Iron : num 2.5 3 1.5 ...
```
---
#### 第3步:转换数据
在进行聚类之前,需要对数据进行标准化处理,以消除不同变量量纲的影响。
使用`apply()`函数计算每一列的标准差:
```R
standard.deviation
```
结果如下(示例):
```
Energy Protein Fat Calcium Iron
120.5 8.5 15.0 5.0 1.0
```
然后,使用`sweep()`函数对数据进行标准化处理:
```R
foodergycnt.stddev
```
结果如下(示例):
```
Energy Protein Fat Calcium Iron
1 3.0 0.94 0.05 2.0 2.5
2 2.2 1.18 0.07 3.0 3.0
3 1.6 2.82 0.67 2.4 1.5
...
```
---
#### 第4步:聚类
使用`kmeans()`函数对标准化后的数据进行聚类分析。假设我们希望将数据分为5个簇:
```R
kmeans_result_5
```
结果如下(示例):
```
K-means clustering with 5 clusters of sizes 20, 25, 15, 20, 20
Cluster means:
Energy Protein Fat Calcium Iron
1 1.2 0.8 0.5 1.5 1.0
2 0.5 1.0 0.8 2.0 1.2
3 1.0 1.2 1.5 1.8 1.5
4 0.8 0.5 0.3 1.2 0.8
5 1.5 1.8 2.0 2.5 2.0
Clustering vector:
[1] 1 2 3 4 5 ...
```
接下来,我们将簇的数量调整为4,并重新运行聚类分析:
```R
kmeans_result_4
```
输出4个簇的聚类向量:
```R
kmeans_result_4$cluster
```
结果如下(示例):
```
[1] 1 2 3 4 1 ...
```
最后,我们可以输出每个簇对应的食品标签:
```R
lapply(split(food.energycontent$Food, kmeans_result_4$cluster), as.character)
```
结果如下(示例):
```
$`1`
[1] "Rice" "Bread"
$`2`
[1] "Chicken" "Beef"
$`3`
[1] "Apple" "Banana"
$`4`
[1] "Milk" "Cheese"
```
---
#### 第5步:可视化聚类结果
为了更直观地展示聚类结果,我们可以生成散点图矩阵:
```R
pairs(food.energycontent[,-1])
```
此外,还可以使用主成分分析(PCA)来简化数据维度,并绘制二维散点图:
```R
pca_result
par(pty = "s") # 设置正方形绘图区域
plot(pca_result$scores[,1:2], col = kmeans_result_4$cluster, pch = 16, main = "PCA Scatter Plot")
```
结果如下(示例):

---
### 总结
通过上述步骤,我们成功地对食品数据进行了K-means聚类分析。聚类结果表明,不同食物可以根据其营养成分被划分为多个类别。这种分析方法可以帮助我们更好地理解食物的营养特性,并为健康饮食提供科学依据。
以上内容就是小编为大家整理的食品安全法中关于食品分类的是哪两个?_K-means聚类分析案例(二)全部内容了,希望能够帮助到各位小伙伴了解情况!
更多全新内容敬请关注多特软件站(www.duote.com)!