时间:2025-05-16关注公众号来源:网络
在人工智能的浩瀚宇宙中,有一颗新星正冉冉升起——Kimi-Audio,它以“Moonshot AI”之名,开启了音频技术的全新纪元。这不仅是一个项目,更是一场对音频处理技术极限的勇敢探索。Kimi-Audio,作为一款开源的音频基础模型,它旨在为开发者和研究者提供一个强大的起点,共同推进音频技术的边界。在语音识别、音频合成、声学场景分析等众多领域,Kimi-Audio正扮演着革新者的角色,其开源的本质,意味着技术的门槛被降低,创新的火花得以在更广阔的社区中燎原。通过整合前沿的机器学习算法与精心设计的架构,Kimi-Audio不仅降低了音频应用开发的复杂性,更激发了无数创意的可能,为音乐制作、智能语音交互、乃至虚拟现实体验的沉浸感提升,提供了坚实的底层支持。在这一开源旅程中,每一行代码都是向未知的迈进,邀请每一位梦想家共同绘制音频技术的未来蓝图。
kimi-audio是由moonshotai推出的开源音频基础模型,专注于音频理解、生成和对话任务。它在超过1300万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。其核心架构采用混合音频输入(连续声学+离散语义标记),结合基于llm的设计,支持并行生成文本和音频标记,同时通过分块流式解码器实现低延迟音频生成。

Kimi-Audio的主要功能包括:
语音识别(ASR):能够将语音信号转换为文本内容,支持多种语言和方言。 语音情感识别(SER):分析语音中的情感信息,判断说话者的情绪状态(如高兴、悲伤、愤怒等),可用于客服系统、情感分析等。 声音事件/场景分类(SEC/ASC):识别和分类环境声音(如汽车喇叭声、狗叫声、雨声等)或场景(如办公室、街道、森林等)。 音频字幕生成(AAC):根据音频内容自动生成字幕,帮助听力障碍者更好地理解音频信息。 音频问答(AQA):根据用户的问题生成相应的音频回答。 端到端语音对话:支持生成自然流畅的语音对话内容。 多轮对话管理:能处理复杂的多轮对话任务,理解上下文信息并生成连贯的语音回应。 语音合成(TTS):将文本内容转换为自然流畅的语音,支持多种音色和语调选择。 音频内容分析:对音频中的语义、情感、事件等进行综合分析,提取关键信息。 音频质量评估:分析音频的清晰度、噪声水平等,为音频处理提供参考。Kimi-Audio的技术原理包括:
混合音频输入:Kimi-Audio采用混合音频输入方式,将输入音频分为两部分:离散语义标记和连续声学特征。离散语义标记通过向量量化技术,将音频转换为离散的语义标记,频率为12.5Hz。连续声学特征使用Whisper编码器提取连续的声学特征,并将其降采样到12.5Hz。这种混合输入方式结合了离散语义和连续声学信息,使得模型能够更全面地理解和处理音频内容。 基于LLM的核心架构:Kimi-Audio的核心是一个基于Transformer的语言模型(LLM),初始化来源于预训练的文本LLM(如Qwen2.57B)。 分块流式解码:Kimi-Audio采用基于流匹配的分块流式解码器,支持低延迟音频生成,通过分块处理音频数据,模型能够在生成过程中实时输出音频,显著降低延迟。支持前瞻机制,进一步优化了音频生成的流畅性和连贯性。 大规模预训练:Kimi-Audio在超过1300万小时的多样化音频数据(包括语音、音乐和各种声音)上进行了预训练,使模型具备强大的音频推理和语言理解能力,能处理多种复杂的音频任务,如语音识别、音频问答、情感识别等。 流匹配模型:用于将离散标记转换为连续的音频信号。 声码器(BigVGAN):用于生成高质量的音频波形,确保了生成音频的自然度和流畅性。Kimi-Audio的项目地址为:
GitHub仓库:Kimi-Audio的性能表现包括:
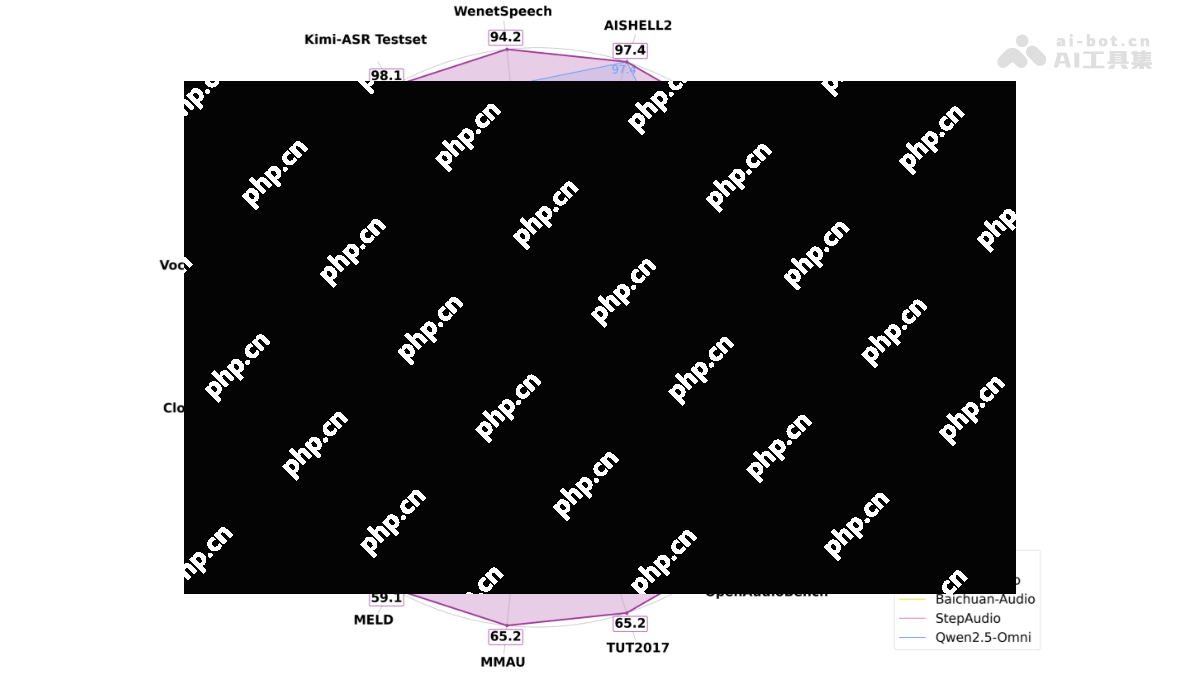
语音识别(ASR):在LibriSpeech测试集上,Kimi-Audio的词错误率(WER)分别达到了1.28%(test-clean)和2.42%(test-other),显著低于其他模型。在AISHELL-1数据集上,其WER仅为0.60%,表现优异。 音频理解:在音频理解任务中,Kimi-Audio在多个数据集上取得了接近或超过SOTA的结果。例如,在ClothoAQA数据集上,其测试集性能达到了73.18%;在VocalSound数据集上,准确率达到了94.85%。 音频问答(AQA):在音频问答任务中,Kimi-Audio在ClothoAQA数据集的开发集上达到了73.18%的准确率,显示出其在理解和生成音频问答内容方面的强大能力。 音频对话:在语音对话任务中,Kimi-Audio在多个基准测试中也表现出色。例如,在VoiceBench的AlpacaEval数据集上,其性能达到了75.73%,在语音对话的流畅性和连贯性方面表现出色。 音频生成:Kimi-Audio在非语音音频生成方面表现出色,在Nonspeech7k数据集上,准确率达到了93.93%,显示出其在生成高质量音频内容方面的能力。Kimi-Audio的应用场景包括:
智能语音助手:Kimi-Audio可以用于开发智能语音助手,支持语音识别、语音合成和多轮对话功能。能理解用户的语音指令并生成自然流畅的语音回应。 语音识别与转录:Kimi-Audio能将语音信号高效转换为文本内容,支持多种语言和方言,适用于会议记录、语音笔记、实时翻译等场景。 音频内容生成:Kimi-Audio可以生成高质量的音频内容,包括语音合成(TTS)、音频字幕生成(AAC)和音频问答(AQA)。能根据文本内容生成自然流畅的语音,也可根据问题生成音频回答,适用于有声读物、视频字幕生成和智能客服等领域。 情感分析与语音情感识别:Kimi-Audio能分析语音中的情感信息,判断说话者的情绪状态(如高兴、悲伤、愤怒等)。 教育与学习:Kimi-Audio在教育领域有多种应用,例如英语口语陪练、语言学习辅助等。可以通过语音交互帮助用户练习发音、纠正语法错误,提供实时反馈。以上就是Kimi-Audio—MoonshotAI开源的音频基础模型的详细内容,更多请关注其它相关文章!