时间:2025-05-16关注公众号来源:网络
在人工智能的广阔天地中,一场视觉与语言的跨界融合正悄然发生。北京理工大学联手上海人工智能实验室,并集合了国内多所顶尖高等学府的智慧力量,共同推出了Mini DALL·E 3——一个前沿的交互式文本到图像生成框架。这一创新平台标志着我国在AI领域又迈出了坚实的一步,尤其是在将抽象文字概念转化为具象视觉艺术方面展现出了革命性的突破。Mini DALL·E 3不仅能够理解复杂的语言指令,还能生成具有高度创意和细节丰富的图像,为艺术创作、设计、教育等多个领域提供了无限可能。它不仅仅是技术的堆砌,更是跨学科合作的典范,预示着未来AI技术在提升人类创造力方面将扮演更加重要的角色。
minidall·e3:一款强大的交互式文本到图像生成框架
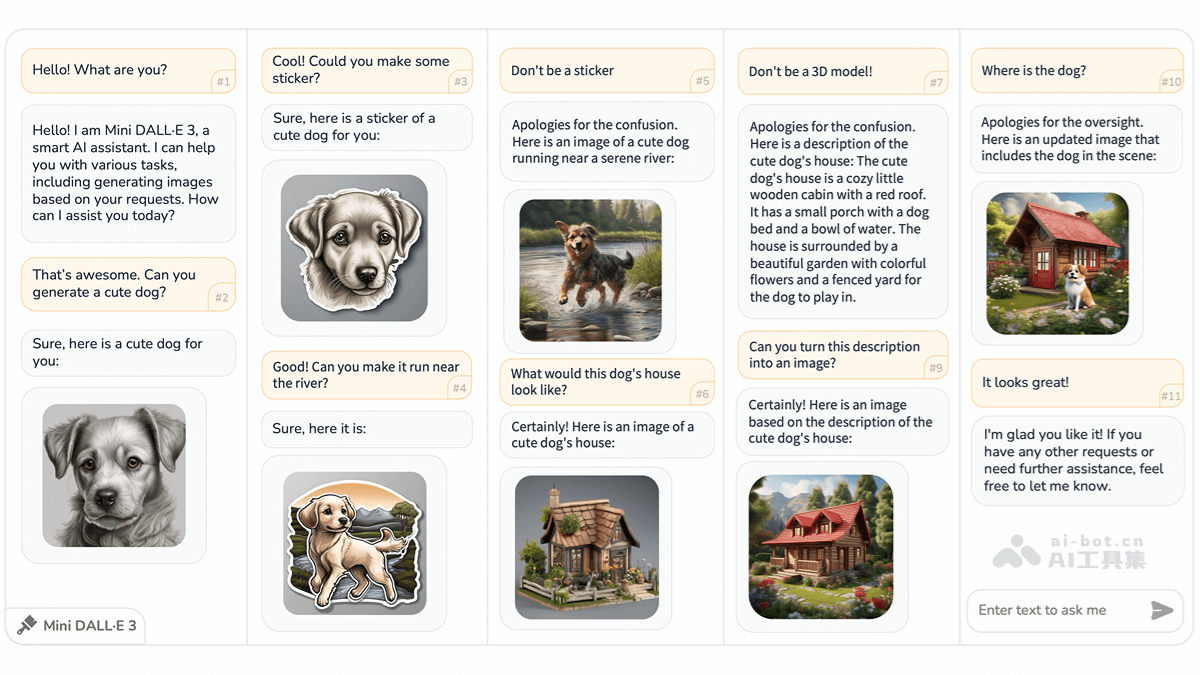
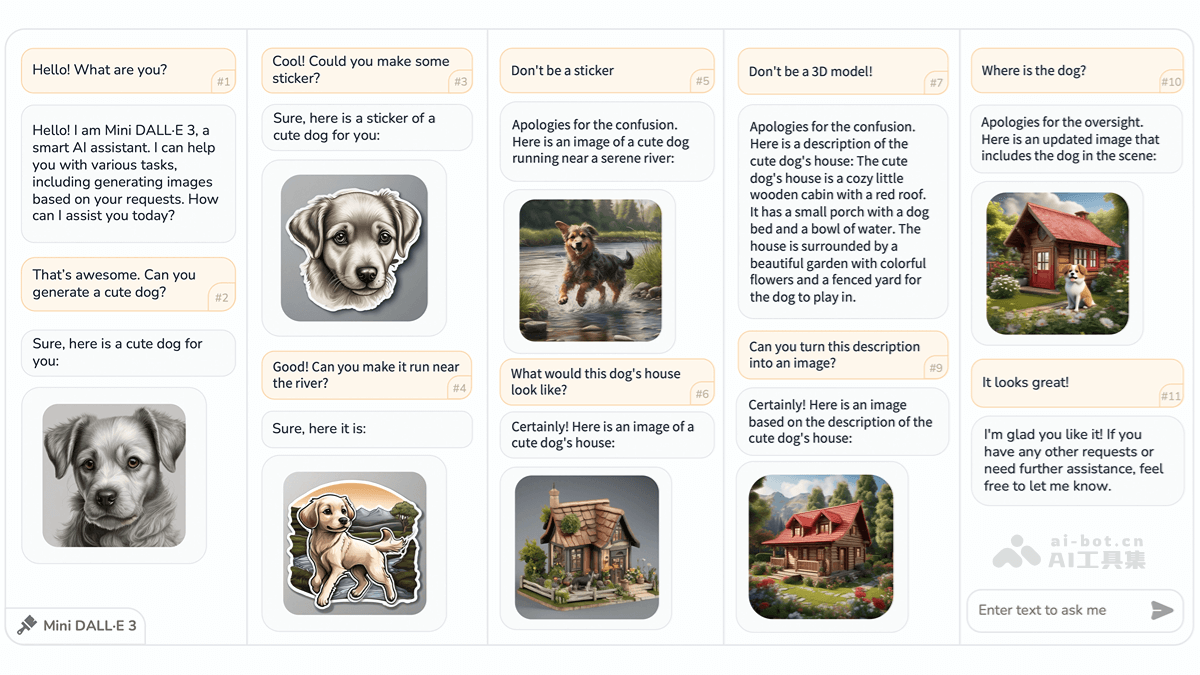
MiniDALL·E3是由北京理工大学、上海AILab、清华大学和香港中文大学联合开发的创新型交互式文本到图像(iT2I)框架。它通过自然语言与用户进行多轮对话,实现高质量图像的生成、编辑和优化。用户只需使用简单的指令逐步完善图像需求,系统便能基于大型语言模型(LLM)和预训练的文本到图像模型(如StableDiffusion),在无需额外训练的情况下生成与文本描述高度吻合的图像。此外,系统还具备问答功能,提供更流畅、便捷的人机交互体验,显著提升图像生成质量。
核心功能:
交互式图像创作:用户以自然语言表达需求,系统即刻生成匹配的图像。 灵活的图像编辑与优化:支持用户修改图像,系统根据反馈迭代优化。 内容连贯性:多轮对话中,图像主题和风格保持一致。 问答功能:用户可随时询问图像细节,系统会结合上下文给出答案。技术架构:
MiniDALL·E3巧妙地结合了大型语言模型(LLM)和文本到图像模型(T2I)。LLM(例如ChatGPT或LLAMA)负责解析用户的自然语言指令,并生成相应的图像描述。通过提示工程技术,系统引导LLM生成符合要求的文本描述,并利用和等特殊标签将图像生成任务转化为文本生成任务。多轮对话中,系统根据上下文和用户反馈不断优化图像描述。一个提示细化模块进一步优化LLM生成的描述,使其更适合后续的T2I模型处理。
T2I模型则负责将LLM生成的图像描述转化为实际图像。系统会根据描述的复杂度和内容变化幅度,选择合适的T2I模型,以确保图像质量和生成效率。一个层次化的内容一致性控制机制,通过运用不同层次的T2I模型,灵活处理细微的风格调整或大幅度的场景重构。系统利用前一次生成的图像作为上下文输入,确保多轮生成中图像内容的一致性。
整个系统架构包含LLM、路由器(router)、适配器(adapter)和T2I模型四个主要组件。路由器负责解析LLM的输出,识别图像生成需求并将其传递给适配器。适配器则将图像描述转换为T2I模型可接受的格式,最终由T2I模型生成图像。
资源链接:
项目官网: GitHub仓库: arXiv技术论文:应用前景:
MiniDALL·E3在创意设计、故事创作、概念设计、教育教学以及娱乐互动等领域拥有广泛的应用前景,例如:
创意内容生成:生成艺术作品、插画、海报等。 故事插图创作:为小说、童话、剧本等生成配套插图。 概念原型设计:在产品设计和建筑设计中快速生成概念图和原型。 教育辅助工具:提供直观的图像辅助学习,帮助理解抽象概念。 互动娱乐体验:在游戏和社交媒体中生成个性化图像,增强用户体验。以上就是MiniDALL·E3—北京理工联合上海AILab等高校推出的交互式文生图框架的详细内容,更多请关注其它相关文章!