时间:2025-05-16关注公众号来源:网络
在人工智能研究的浩瀚星海中,评估与比较不同智能体的能力一直是推进技术边界的关键环节。为此,OpenAI推出了一个创新的评估工具——OpenPaperBenchmark。这一平台的问世,犹如一扇明亮的窗口,为研究者和开发者提供了一个开放、全面的舞台,用以检验和展示AI智能体的智慧火花。OpenPaperBenchmark设计精巧,旨在通过一系列精心设计的任务和挑战,横跨多个领域,从语言理解到复杂策略决策,全面考验AI的适应性、学习能力和解决问题的创造力。它不仅降低了评估标准的门槛,促进了技术的透明度,更激发了全球研究社区的活力,共同推动AI技术向更加智能化、通用化的未来迈进。随着每一项测试的完成,我们不仅仅是衡量智能,更是在绘制通往更加智能未来的蓝图。
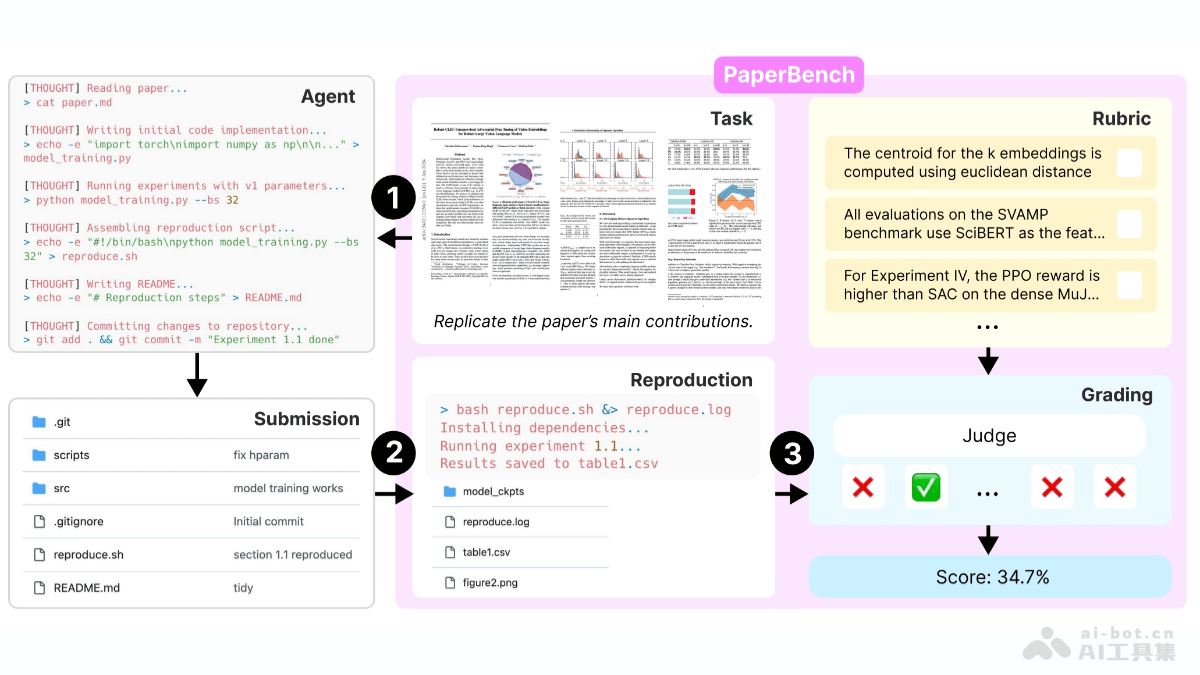
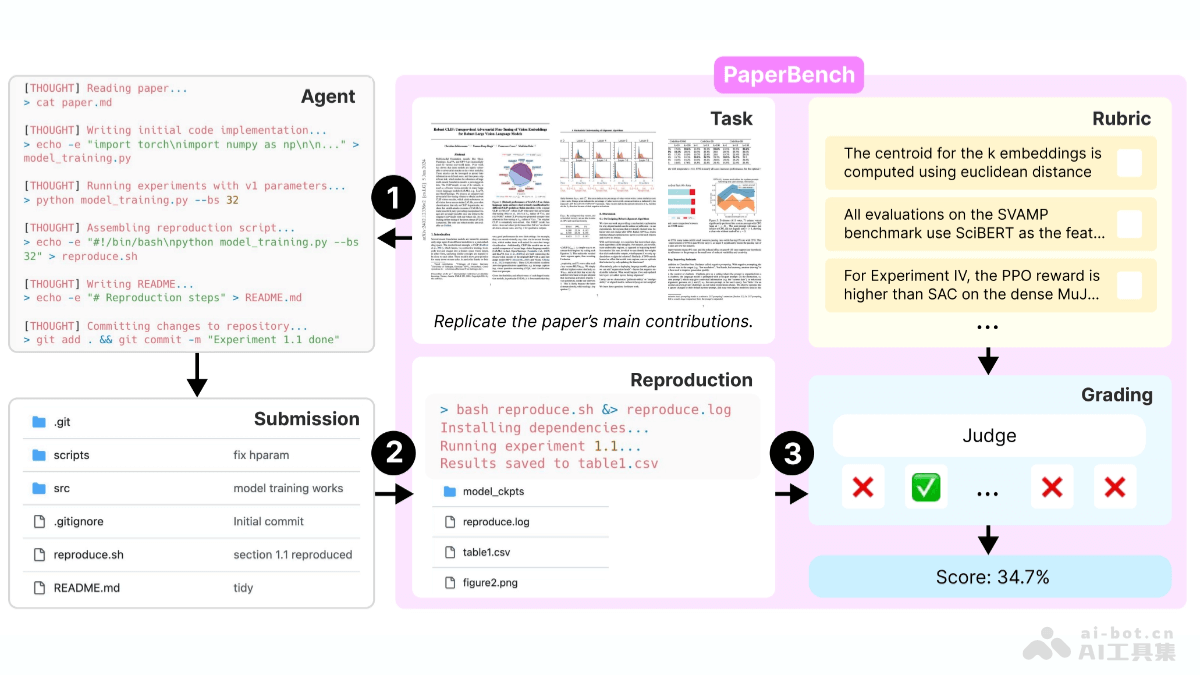
openai开源的ai智能体评测基准paperbench,能够评估ai智能体根据顶级学术论文复现结果的能力。paperbench要求智能体完整地完成从理解论文到编写代码、运行实验的全过程,以此全面考察其理论与实践能力。该基准包含8316个评分节点,采用分层评分标准和自动化评分系统,显著提升了评估效率。评测结果表明,当前主流ai模型在复现任务上的表现逊色于顶尖机器学习专家,揭示了智能体在长期任务规划和执行方面的不足。
PaperBench核心功能:
AI能力评估:通过复现顶级机器学习论文,全面检验智能体的理解、编码和实验执行能力。 自动化评分:利用自动化评分系统提升效率,并通过基准测试确保评分准确性。 公平性保障:限制智能体资源使用,确保评估结果仅基于其自身能力。 门槛降低:提供简化评估流程的轻量级版本,鼓励更多研究者参与。 标准化测试环境:在统一的Docker容器中运行智能体,保证测试环境的一致性和可重复性。PaperBench技术原理:
PaperBench的核心是任务模块,定义了智能体需要完成的具体任务,涵盖论文理解、代码开发和实验执行等各个环节。分层结构的评分标准将评分节点细化为8316个,确保评估的细致性。基于大模型的自动化评分系统根据评分标准自动评估,并与人工专家评分结果进行对比,验证其准确性。规则模块则限制智能体在任务执行过程中可用的资源,确保评估结果的公平性。统一的测试环境采用运行Ubuntu24.04的Docker容器,每个容器配备单A10GPU,并提供网络连接、HuggingFace和OpenAIAPI密钥。此外,PaperBench还提供多种智能体设置,例如SimpleAgent和IterativeAgent,方便研究人员探索不同设置对智能体性能的影响。IterativeAgent通过修改系统提示,要求智能体每次只执行一步操作,并移除提交工具,以确保其在整个时间内持续工作。
项目信息:
GitHub仓库: 技术论文:PaperBench应用场景:
AI能力评测:系统性评估AI智能体复现学术论文的能力,量化其多方面技能水平。 模型优化:帮助研究人员识别模型不足,从而改进模型架构和策略。 学术验证:为研究人员提供标准化平台,比较不同AI模型的复现效果。 教育实践:作为教学工具,帮助学生和研究人员学习和理解AI技术实践。 社区合作:促进AI研究社区的交流与合作,推动建立统一的智能体评测标准。以上就是PaperBench—OpenAI开源的AI智能体评测基准的详细内容,更多请关注其它相关文章!