时间:2025-05-19 关注公众号 来源:网络
在不远的2025年,数字世界的帷幕悄然拉开新的篇章。科技的浪潮中,麻省理工学院的精英们破解了时间的密码,用智慧编织了一场视觉革命。《历史引导的梦幻编织者》——这不是一部寻常的科幻小说,而是一次对未来的深度探索。故事围绕着DFOT,一个革命性的算法,它像一位时间的魔术师,将视频的边界扩展至前所未有的千帧之遥。
在虚拟与现实交织的边缘,主角陈博远,一位年轻的科研才俊,揭开了diffusionforcingtransformer的神秘面纱,挑战着视频生成技术的极限。他的发明,不仅捕捉到了每一帧间的细腻情感,更是在数字海洋中重构了历史与未来的对话。但随着技术的飞跃,伦理与隐私的阴影也开始悄悄蔓延。陈博远和他的团队不仅要面对技术的极限,更要解决由这项技术引发的社会议题。
这是一场关于创新的冒险,一段探索未知的旅程。在《历史引导的梦幻编织者》中,每一个像素都跳动着未来的心脏,每一次视频的流畅播放都是对人类创造力的致敬。当千帧长视频不再是梦想,我们是否准备好迎接一个全新的表达时代?在这本书里,读者将被带入一个既真实又超现实的未来,见证科技如何重塑我们的视觉叙事,以及它背后那群不凡的梦想家。
2025年,视频生成技术,特别是基于扩散模型的视频生成,持续发展创新,涌现出众多令人惊艳的文生视频和图生视频模型。然而,长视频生成一直是该领域的一大难题。麻省理工学院(mit)团队近期发表的论文《history-guidedVideodiffusion》提出了一种名为diffusionforcingtransformer(dfot)的全新算法,无需改变现有模型架构,即可实现视频生成长度提升近50倍,达到近千帧。

论文地址: 项目主页:
生成的视频长度惊人,需截短并降低帧率才能展示。先睹为快:

现有视频扩散模型广泛采用无分类器引导(CFG)来提升采样质量,但通常仅利用首帧信息,忽略了后续帧的重要性。MIT团队的研究表明:历史信息是提升视频生成质量的关键!

该论文通过混合长短历史模型的预测结果,提出了一系列“历史引导”算法,显著提升了视频扩散模型的质量、生成长度、鲁棒性和可组合性。

在X平台上,论文共同一作陈博远分享的研究成果获得了极高的关注度。
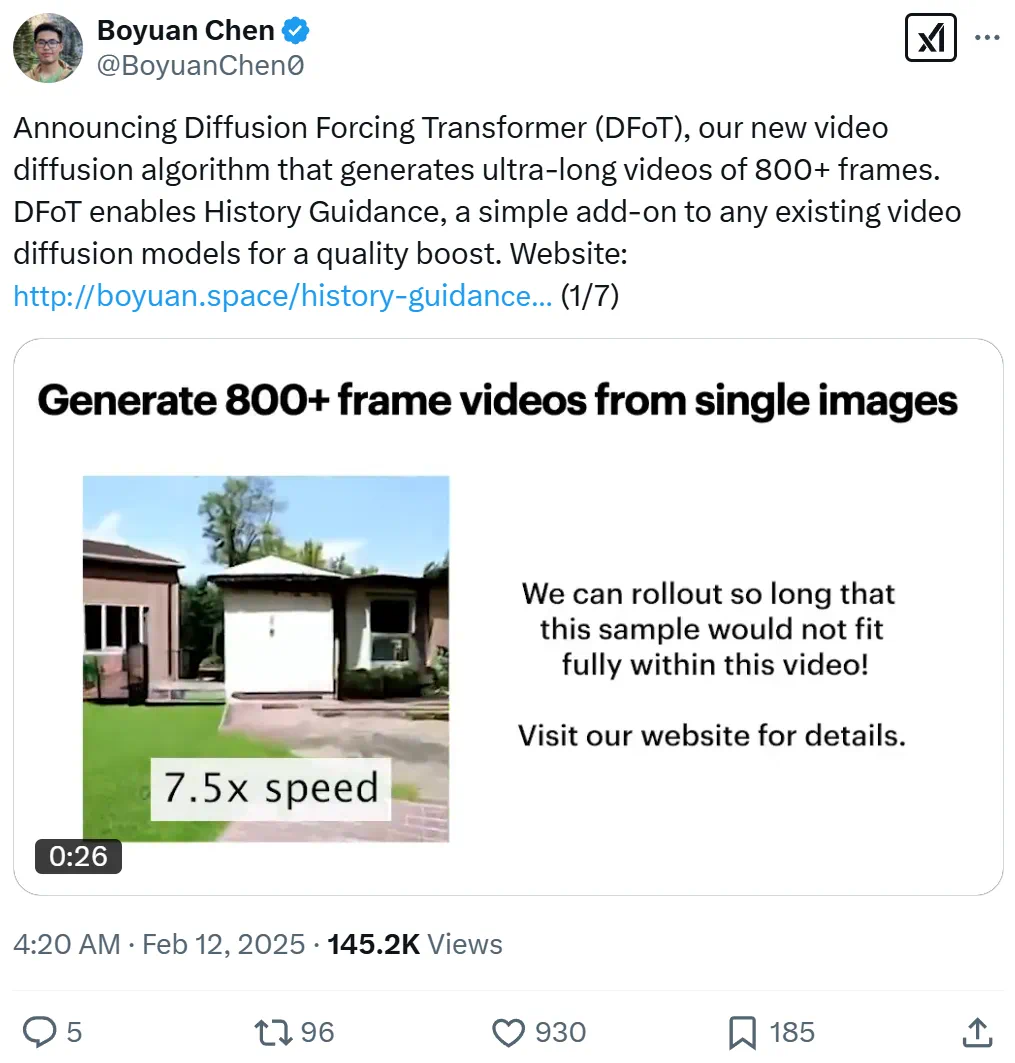
谷歌研究科学家GeorgeKopanas高度评价了这项工作,认为其成果令人印象深刻。

核心方法:
论文首先训练了一个能够根据不同历史信息进行去噪预测的视频模型,包括不同长度的历史、历史的不同子集以及特定频率域的历史。然而,现有模型架构缺乏这种灵活性。DFoT算法巧妙地将DiffusionForcing中的噪声掩码概念引入视频生成架构,通过控制噪声掩码来实现对任意子序列的预测,无需修改模型架构。
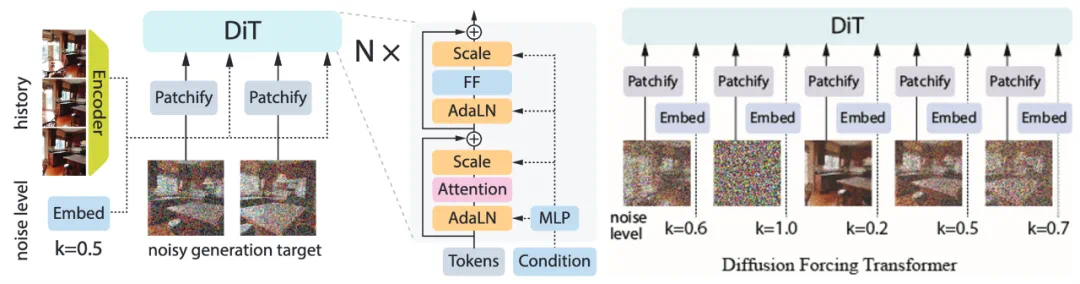
DFoT训练完成后,可以灵活地进行采样。例如,通过控制噪声掩码,可以选择使用前几帧作为条件,或进行无条件生成,或使用特定长度的历史作为条件。
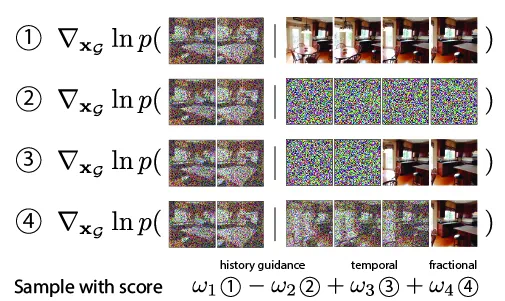
基于此,论文提出了一系列“历史引导”算法,进一步提升了模型性能。
实验结果:
DFoT在Kinetics600数据集上超越了所有同架构的视频扩散算法,甚至与谷歌的闭源大模型结果不相上下。在RealEstate10K数据集上,DFoT实现了单图生成近千帧的突破性成果。
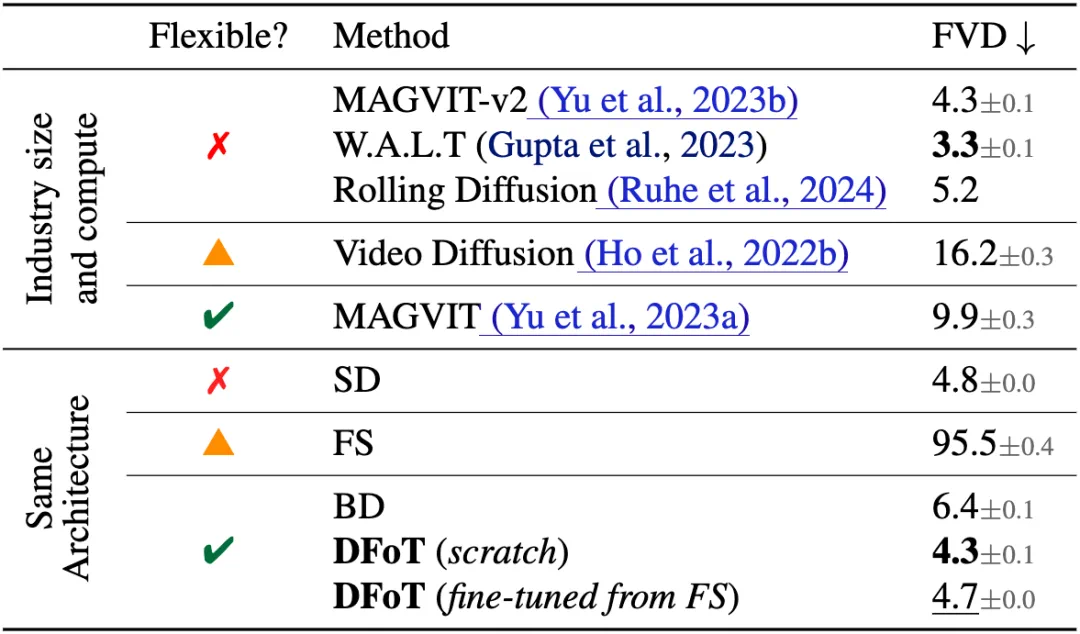


总结:
DFoT算法及其提出的“历史引导”策略显著提升了视频扩散模型的性能。该研究提供了完整的开源实现和Huggingface在线体验,方便研究者进一步探索。Huggingface地址:
以上就是千帧长视频时代到来!MIT全新扩散算法让任意模型突破时长极限的详细内容,更多请关注其它相关文章!
上一篇:十大免费的ai编程工具推荐