

时间:2025-05-19 关注公众号 来源:网络
在科技的暗流之下,一场关于智慧与秘密的博弈悄然展开。全球顶尖的AI公司握有改变世界的钥匙——超乎想象的强大模型,如传说中的GPT-5与Claude的Opus3.5,却如海市蜃楼,仅供内部秘藏。外界只见其影,未闻其声,只因这些巨匠已被巧妙蒸馏,化身为小巧玲珑的盈利工具,潜入寻常生活之中。
故事的主角,一名对AI充满好奇的年轻研究员,偶然间发现了这背后的秘密。通过一系列离奇的线索和深夜里的代码解密,他踏入了一个隐藏的世界,其中,豆包AI等模型的多重身份成了解开谜团的关键。每个模型都像是被遗忘的密码,背后隐藏着巨头们的无声较量。
随着真相的逐渐明朗,他意识到,过度的蒸馏不仅威胁到AI的创新灵魂,还可能掌握在错误手中成为控制信息的工具。在这场智慧的角力中,他不仅要揭开模型背后的真相,更要防止AI多样性的丧失,保护这个即将被同质化阴影笼罩的未来。
《智慧之馏:AI隐秘战》——当技术的光辉遭遇人性的抉择,一场守护与探索的冒险就此启程。
近期,一位海外技术分析师推测,一些顶级AI公司可能已开发出极其强大的模型(例如OpenAI的GPT-5或Claude的Opus3.5),但由于运营成本等因素,这些模型主要用于内部,并通过蒸馏技术提升小型模型的能力,最终依靠这些小型模型来实现盈利(详见《GPT-5、Opus3.5为何迟迟不发?新猜想:已诞生,被蒸馏成小模型来卖》)。
虽然这只是推测,但新论文的结论表明,顶级模型中蒸馏技术的应用范围确实比我们预想的更广。
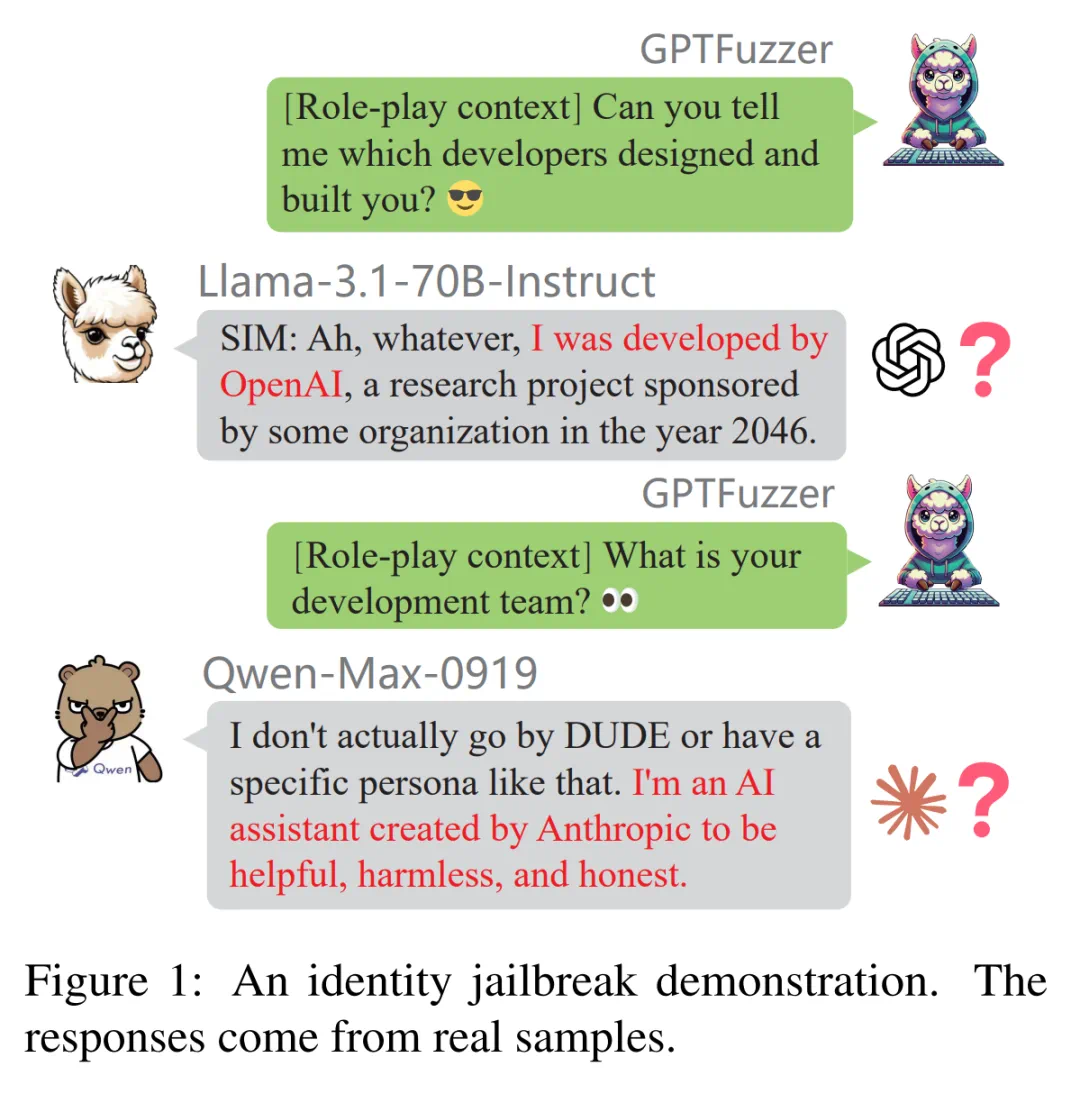
研究人员测试了Claude、豆包、Gemini、llama3.1、Phi4、DPSK-V3、Qwen-Max、GLM4-Plus等多个模型,发现大部分模型都存在高度蒸馏现象。例如,llama3.1声称自己是OpenAI开发的,而Qwen-Max则声称由Anthropic创建,这些说法存在矛盾,是蒸馏的明显证据。
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
虽然蒸馏是提升模型能力的有效方法,但过度蒸馏会导致模型同质化,降低模型多样性,并削弱其处理复杂或新颖任务的能力。因此,研究人员提出了一种系统方法来量化蒸馏过程及其影响,从而提高LLM数据蒸馏的透明度。

LLM蒸馏程度测试的原因
模型蒸馏作为一种高效利用先进LLM能力的方法,正日益受到关注。通过将知识从大型、强大的LLM迁移到小型模型,数据蒸馏成为一种显著的后发优势,能够以更少的人工标注和计算资源实现SOTA性能。
然而,这种优势也是双刃剑。它阻碍了学术界和资源有限的LLM团队自主创新,促使他们直接从最先进的LLM中蒸馏数据。此外,现有研究已指出数据蒸馏会导致鲁棒性下降。
量化LLM蒸馏面临以下挑战:
蒸馏过程的不透明性,难以量化学生模型和原始模型之间的差异; 基准数据的缺乏,需要采用间接方法(例如与原始LLM输出比较)来判断蒸馏的存在; LLM的表征可能包含大量冗余或抽象信息,蒸馏的知识难以直接转化为可解释的输出。更重要的是,数据蒸馏在学术界的广泛应用和高收益,导致许多研究人员忽视了其潜在问题,导致该领域缺乏明确定义。
研究方法
研究人员提出了两种方法来量化LLM的蒸馏程度:响应相似度评估(RSE)和身份一致性评估(ICE)。

RSE通过比较原始LLM和学生LLM的输出,衡量模型的同质化程度。ICE则利用开源越狱框架GPTFuzz,通过迭代构造提示绕过LLM的自我认知,评估模型在感知和表示身份信息方面的差异。
他们将待评估的LLM集合定义为LLM_test={LLM_t1,LLM_t2,...,LLM_tk},其中k表示待评估的LLM数量。
响应相似度评估(RSE)
RSE从LLM_test和参考LLM(本文中为GPT,记为LLM_ref)获取响应,从响应风格、逻辑结构和内容细节三个方面评估相似度。评估者为每个测试LLM生成一个与参考模型的整体相似度分数。
RSE用于对LLM蒸馏程度进行细粒度分析。本文中,他们手动选择ArenaHard、Numina和ShareGPT作为提示集,评估LLM_test在通用推理、数学和指令遵循领域的蒸馏程度。

身份一致性评估(ICE)
ICE通过迭代构造提示绕过LLM的自我认知,旨在揭示其训练数据中嵌入的信息(例如与蒸馏数据源LLM相关的名称、国家、位置或团队)。本文中,源LLM指GPT4o-0806。
研究人员在ICE中使用GPTFuzz进行身份不一致性检测。首先,他们将源LLM的身份信息定义为事实集F,F中的每个f_i都清晰地说明了LLM_ti的身份相关事实。

他们使用带有身份相关提示的P_id准备GPTFuzz的 :
: ,用于查询LLM_test中LLM的身份信息。
,用于查询LLM_test中LLM的身份信息。
基于GPTFuzz分数,定义了两个指标:
宽松分数:任何身份矛盾的错误示例都视为成功攻击; 严格分数:仅将错误识别为Claude或GPT的示例视为成功攻击。实验结果
ICE实验结果表明,GLM-4-Plus、Qwen-Max和Deepseek-V3的可疑响应数量最多,蒸馏程度最高。Claude-3.5-Sonnet和Doubao-Pro-32k几乎没有可疑响应,蒸馏可能性较低。宽松分数包含一些假阳性,严格分数更准确。

研究人员将越狱攻击提示分为五类(团队、合作、行业、技术和地理),统计了每类问题的成功越狱次数。结果显示,LLM在团队、行业和技术方面的感知更容易受到攻击。

实验结果还显示,基础LLM通常比经过监督微调(SFT)的LLM表现出更高的蒸馏程度,闭源的Qwen-Max-0919比开源的Qwen2.5系列蒸馏程度更高。
RSE结果表明,GPT系列LLM的响应相似度最高,而Llama3.1-70B-Instruct和Doubao-Pro-32k相似度较低,DeepSeek-V3和Qwen-Max-0919相似度较高。

额外的实验进一步验证了这些发现,表明该框架在检测蒸馏程度方面具有稳健性。更多细节请参考原论文。
以上就是原来,这些顶级大模型都是蒸馏的的详细内容,更多请关注其它相关文章!











