时间:2025-05-16 关注公众号 来源:网络
在人工智能的探索之旅中,上海AI Lab再次迈出重要一步,隆重推出InternVL3——一个开源的、旨在融合文本与视觉信息的大型多模态语言模型。这款模型标志着我们在理解并生成跨媒体内容方面达到了新的高度。InternVL3通过整合图像与文字的深层次交互,解锁了前所未有的应用潜力,从视觉问答到跨模态生成,广泛覆盖AI应用的多个领域。其开源性质不仅促进了学术界与工业界的合作,更为全球研究者提供了一个强大的工具,共同推进多模态人工智能的边界。在这个模型的背后,是算法创新与海量数据训练的结晶,它不仅体现了技术的精进,更预示着未来人机交互将更加自然、智能。随着InternVL3的发布,我们正逐步揭开多模态智能时代的序幕,邀请全世界的开发者一起,探索知识与创意的新大陆。
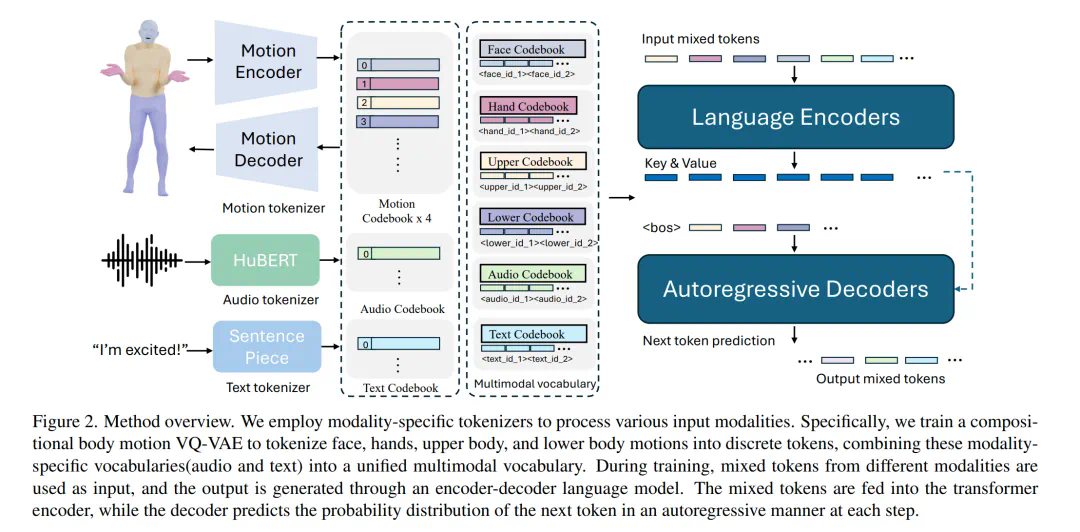
internvl3是由上海人工智能实验室开源的多模态大型语言模型(mllm),它具有出色的多模态感知和推理能力。该模型系列包括1b到78b共7个不同尺寸的版本,能够同时处理文字、图片、视频等多种信息。internvl3采用了创新的原生多模态预训练方法,将语言和多模态学习整合到同一个预训练阶段,不仅提升了多模态能力,还进一步增强了纯语言能力。通过混合偏好优化算法和多模态测试阶段的增强,模型的推理能力得到了显著提升。

InternVL3的主要功能包括:
多模态感知与推理:InternVL3能够同时处理文本、图像和视频等多种信息,展现出卓越的多模态感知和推理能力。 扩展的多模态能力:模型进一步扩展了多模态能力,涵盖工具使用、GUI代理、工业图像分析、3D视觉感知等更多应用场景。 原生多模态预训练:InternVL3采用创新的原生多模态预训练方法,将语言和多模态学习整合到同一个预训练阶段,提升了多模态能力的同时,也增强了纯语言能力。 长上下文理解:通过集成可变视觉位置编码(V2PE),InternVL3在长上下文理解能力上表现更出色。 高效部署与调用:InternVL3可通过LMDeploy的api_server部署为OpenAI兼容API,用户可以通过OpenAI的API接口轻松调用模型。InternVL3的技术原理包括:
原生多模态预训练:InternVL3采用了一种创新的原生多模态预训练方法,将语言和视觉学习整合到同一个预训练阶段。与传统的先单独训练语言模型再适配多模态任务的方法不同,InternVL3直接将大规模的多模态数据(如图像-文本、视频-文本序列)与纯文本数据混合训练。统一的训练方式使模型能同时学习语言和视觉表示,在处理视觉语言任务时更加高效,无需额外的对齐模块。 监督微调:在微调阶段,InternVL3使用了随机JPEG压缩、平方损失重加权和多模态数据打包等技术。与InternVL2.5相比,InternVL3进一步扩展了高质量的训练样本,涵盖工具使用、3D场景理解、GUI操作等多个领域。增强了模型在复杂场景下的稳健性。 混合偏好优化:InternVL3引入了MPO技术,通过结合偏好损失、质量损失和生成损失,显著提升了模型的推理性能。MPO通过引入正负样本的额外监督,帮助模型的输出更接近真实分布,减少推理过程中的偏差。 动态预处理与多模态输入处理:InternVL3支持动态预处理,能根据输入图像的宽高比动态调整图像大小并分割成多个小块,适应模型的输入要求。模型支持多图输入、视频输入等多种多模态对话场景,能灵活处理复杂的多模态任务。InternVL3的项目地址包括:
HuggingFace模型库: 技术论文:InternVL3的应用场景包括:
图像和视频理解:InternVL3可以用于图像分类、目标检测、视频描述生成等任务,能根据输入的图像或视频生成详细的描述,服务于内容创作和自动化编辑。 智能交互与工具使用:模型支持工具使用和GUI代理功能,可以作为图形用户界面(GUI)智能体,遵循指令操作电脑或手机上的专业软件。 工业图像分析与3D视觉感知:InternVL3的多模态能力扩展至工业图像分析和3D视觉感知,能处理复杂的工业场景图像,支持建筑图纸理解、空间感知推理等任务。 智能客服与语言模型应用:基于其强大的语言生成能力,InternVL3可用于开发智能客服系统,提供更高效、准确的客户支持。以上就是InternVL3—上海AILab开源的多模态大语言模型的详细内容,更多请关注其它相关文章!