

ʱ�䣺2025-05-16��ע���ں���Դ������
�����ֻ�ʱ������Ϣ�ĸ�Ч�����������Ϊ���������Ĺؼ����ٶ��ɽ�����Ϊ�������ȵ����ѧϰƽ̨�������Ƴ���������Եijɹ�����PP-DocBee��һ��רΪ�ĵ�ͼ����������Ķ�ģ̬��ģ�͡�PP-DocBee����������ʶ������Ȼ���Դ�����ǰ�ؼ�����ּ�ڽ�����ӳ������ĵ������ܽ�����������ȡ���⡣��һģ�͵ĵ�������־������ֽ���칫��֪ʶ�Զ�������������������Ҫһ����ͨ�����ѧϰ��������PP-DocBee�ܹ�ȷʶ������������ָ�ʽ�����Ե��ĵ�ͼ���������˹���Ч�ʣ�ҲΪѧ���о�����ҵ�����������ṩ��ǿ������ݴ������ߡ��������Ǽ�����ͻ�ƣ����������ܻ���Ϣ����ʱ����һ��Ծ����Ԥʾ��δ���ĵ��������������ܻ���������
����pp-docbee���ٶȷɽ����ĵ�ͼ�������ģ̬��ģ��
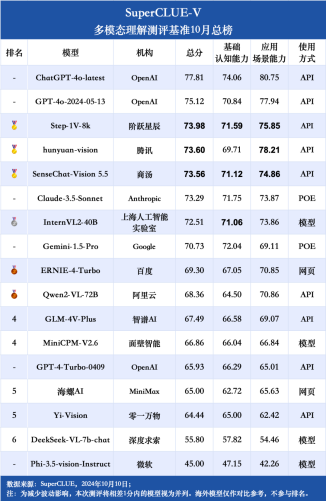
�����ٶȷɽ���PaddlePaddle���Ƴ���PP-DocBee����һ��רע���ĵ�ͼ������Ķ�ģ̬��ģ�͡�������ViT+MLP+LLM�ܹ����߱�ǿ��������ĵ������������ܹ���Ч�����ĵ��е����֡������ͼ���ȶ�����Ϣ����Ȩ��ѧ�������У�PP-DocBee��ͬ������ģ����ȡ��������ˮƽ�����ڰٶ��ڲ�ҵ����չ�ֳ���������ij��������������������������Ż���PP-DocBee��Ӧ�ٶȸ��죬ͬʱ���ָ��������������ģ���������ĵ��ʴ𡢸����ĵ������ȶ��ֳ�������֧�ֶ��ֲ���ʽ��Ϊ�ĵ������ṩ��Ч�����ܵĽ��������
����
������:
������ģ̬�ĵ�����:PP-DocBee�ܹ���ʶ��������ĵ�ͼ���е����֡������ͼ����Ԫ�أ�֧���ı���ͼ��Ķ�ģ̬���롣������Ч�ĵ��ʴ�:�����ĵ����ݣ�PP-DocBee�ܹ�����ȷ�Ĵ𰸡������ṹ����Ϣ��ȡ:���ĵ��еı���ͼ������Ϣת��Ϊ�ṹ�����ݣ�������������ʹ�������������ԭ��:
����PP-DocBee�����Ƚ���ViT���Ӿ�Transformer����MLP������֪������LLM��������ģ�ͣ��ܹ�������Ӿ�������ģ�͵����ƣ�ʵ�ֶ˵��˵��ĵ����⡣Ϊ�˿˷������ĵ��������ս��PP-DocBee�������ĵ�������������������������OCRСģ����LLM��ģ�͵Ľ���Լ�������Ⱦ�����ͼ���������ɼ�����ѵ�������У�ģ��ʹ���˸����resize��ֵ������ʱ���ͼ����еȱ����Ŵ��Ի�ȡ��ȫ����Ӿ����������⣬PP-DocBee�����ʹ���˶����ĵ��������ݣ�ͨ��VQA��OCR��ͼ������ѧ�����ȣ���������������Ȼ��ƣ�ƽ�ⲻͬ���ݼ����������죬������OCR������������ģ������������ͼƬ�ϵ�����������
������ȡ��ʽ��Ӧ�ó���:
����GitHub:��������Demo:����PP-DocBee�㷺�����ڶ������
������������:����������������Ʊ���ĵ�����ȡ�ؼ����ݣ����������������ƹ�����������������:������ͬ��������ĵ���������λ�ؼ����֧�ַ��ɺϹ���顣����ѧ���о�:��ȡ�����е����ֺ�ͼ����Ϣ���������������о�������������ҵ�ĵ�����:��ȡ�ͽṹ���ڲ��ĵ����ݣ��Ż��ĵ������������̡�������������:�����̲ĺ��Ծ���������ѧ��Դ����������ѧϰ���������Ͼ���PP-DocBee���ٶȷɽ��Ƴ����ĵ�ͼ�������ģ̬��ģ�͵���ϸ���ݣ��������ע����������£�








����������Դ�����磬��������վ���������ַ�������Ȩ�棬����ϵ����ɾ��������վΪ��ӯ��������վ��
�绰��13918309914
QQ��1967830372


