时间:2025-05-16关注公众号来源:网络
在数字内容创作的浩瀚星海中,阿里巴巴前沿技术研究的光芒再次闪耀,推出了一项革命性的技术成就——“万相首尾帧驱动模型”,这一创举标志着视频生成技术迈入了一个全新的开源时代。该模型颠覆了传统视频制作的繁琐流程,聚焦于首尾帧的创意设计,中间内容自动生成的巧妙理念,大大降低了高质量视频内容创作的门槛。通过阿里通义的强大算法支撑,创作者只需提供视频的起始与结束画面,中间的视觉故事便能自动编织,既保留了创意的火花,又实现了高效产出,为内容创作者提供了无限想象空间和便捷工具。这不仅仅是技术的跃进,更是激发创意经济潜能的一大步,预示着个性化视频内容制作将迎来前所未有的繁荣景象。
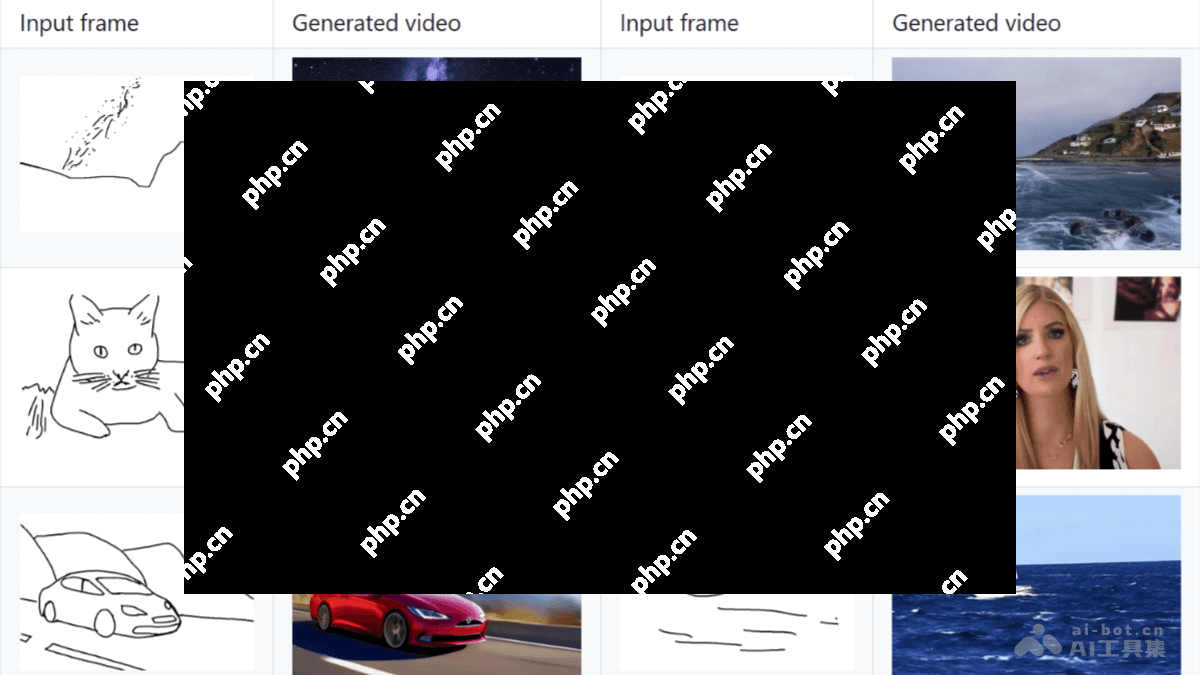
万相首尾帧模型(wan2.1-flf2v-14b)是一款开源的14b参数规模的首尾帧生成视频模型。该模型可以根据用户提供的首帧和尾帧图像,自动生成流畅的高清视频过渡效果,并支持多种风格和特效变换。万相首尾帧模型基于先进的dit架构,结合高效的视频压缩vae模型和交叉注意力机制,确保生成视频在时空上高度一致。用户可以在通义万相官网免费体验。
 万相首尾帧模型的主要功能 首尾帧生成视频:根据用户提供的首帧和尾帧图像,生成时长5秒、720p分辨率的自然流畅视频。 多种风格支持:能够生成写实、卡通、漫画、奇幻等风格的视频。 细节复刻与自然动作:精确复刻输入图像细节,生成生动自然的动作过渡。 指令遵循:通过提示词控制视频内容,如镜头移动、主体动作、特效变化等。 万相首尾帧模型的技术原理 DiT架构:核心架构基于DiT(DiffusioninTIMe)架构,专门用于视频生成。基于FullAttention机制精确捕捉视频的长时程时空依赖关系,确保生成视频在时间和空间上的高度一致性。 视频压缩VAE模型:引入高效的视频压缩VAE(VariationalAutoencoder)模型,显著降低运算成本,同时保持生成视频的高质量。使高清视频生成更加经济且高效,支持大规模的视频生成任务。 条件控制分支:用户提供的首帧和尾帧作为控制条件,通过额外的条件控制分支实现流畅且精准的首尾帧变换。首帧与尾帧与若干零填充的中间帧拼接,构成控制视频序列。序列进一步与噪声及掩码(mask)拼接,作为扩散变换模型(DiT)的输入。 交叉注意力机制:提取首帧和尾帧的CLIP语义特征,通过交叉注意力机制(Cross-AttentionMechanism)注入到DiT的生成过程中。画面稳定性控制确保生成视频在语义和视觉上与输入的首尾帧保持高度一致。 训练与推理:训练策略基于数据并行(DP)与完全分片数据并行(FSDP)相结合的分布式策略,支持720p、5秒视频切片训练。分三个阶段逐步提升模型性能: 第一阶段:混合训练,学习掩码机制。 第二阶段:专项训练,优化首尾帧生成能力。 第三阶段:高精度训练,提升细节复刻与动作流畅性。 万相首尾帧模型的项目地址 GitHub仓库: HuggingFace模型库: 万相首尾帧模型的应用场景 创意视频制作:快速生成场景切换或特效变化的创意视频。 广告与营销:制作吸引人的视频广告,提升视觉效果。 影视特效:生成四季交替、昼夜变化等特效镜头。 教育与演示:制作生动的动画效果,辅助教学或演示。 社交媒体:生成个性化视频,吸引粉丝,提升互动性。
万相首尾帧模型的主要功能 首尾帧生成视频:根据用户提供的首帧和尾帧图像,生成时长5秒、720p分辨率的自然流畅视频。 多种风格支持:能够生成写实、卡通、漫画、奇幻等风格的视频。 细节复刻与自然动作:精确复刻输入图像细节,生成生动自然的动作过渡。 指令遵循:通过提示词控制视频内容,如镜头移动、主体动作、特效变化等。 万相首尾帧模型的技术原理 DiT架构:核心架构基于DiT(DiffusioninTIMe)架构,专门用于视频生成。基于FullAttention机制精确捕捉视频的长时程时空依赖关系,确保生成视频在时间和空间上的高度一致性。 视频压缩VAE模型:引入高效的视频压缩VAE(VariationalAutoencoder)模型,显著降低运算成本,同时保持生成视频的高质量。使高清视频生成更加经济且高效,支持大规模的视频生成任务。 条件控制分支:用户提供的首帧和尾帧作为控制条件,通过额外的条件控制分支实现流畅且精准的首尾帧变换。首帧与尾帧与若干零填充的中间帧拼接,构成控制视频序列。序列进一步与噪声及掩码(mask)拼接,作为扩散变换模型(DiT)的输入。 交叉注意力机制:提取首帧和尾帧的CLIP语义特征,通过交叉注意力机制(Cross-AttentionMechanism)注入到DiT的生成过程中。画面稳定性控制确保生成视频在语义和视觉上与输入的首尾帧保持高度一致。 训练与推理:训练策略基于数据并行(DP)与完全分片数据并行(FSDP)相结合的分布式策略,支持720p、5秒视频切片训练。分三个阶段逐步提升模型性能: 第一阶段:混合训练,学习掩码机制。 第二阶段:专项训练,优化首尾帧生成能力。 第三阶段:高精度训练,提升细节复刻与动作流畅性。 万相首尾帧模型的项目地址 GitHub仓库: HuggingFace模型库: 万相首尾帧模型的应用场景 创意视频制作:快速生成场景切换或特效变化的创意视频。 广告与营销:制作吸引人的视频广告,提升视觉效果。 影视特效:生成四季交替、昼夜变化等特效镜头。 教育与演示:制作生动的动画效果,辅助教学或演示。 社交媒体:生成个性化视频,吸引粉丝,提升互动性。 以上就是万相首尾帧模型—阿里通义开源的首尾帧生视频模型的详细内容,更多请关注其它相关文章!