时间:2025-05-16关注公众号来源:网络
在人工智能的浩瀚领域,当我们期望模型能够像人类一样深入思考,DeepSeek-R1等长推理模型成为了研究的焦点。然而,一项最新的研究表明,这些被寄予厚望的智能体并非无懈可击。它们在面对复杂问题时,似乎遭遇了意想不到的“思考不足”困境。这一发现颠覆了我们对高级AI推理能力的认知,揭示了即便在深度学习和长序列推理技术的加持下,模型仍可能陷入理解的浅滩。这不仅是一个技术挑战的信号,更是对当前AI发展方向的一次深刻反思。我们开始意识到,构建更加贴近人类复杂思维过程的AI,还需跨越理解的深度与广度上更多的未知障碍。本文将深入剖析这一现象,探讨背后的原因及其对未来AI研究的潜在影响。
腾讯ailab联合苏州大学、上海交通大学团队的研究揭示了长推理模型的“思考不足”现象,并提出了一种改进方法。这项研究发表于arxiv,通讯作者为腾讯专家研究员涂兆鹏。

研究发现,类似OpenAIo1等长推理模型,虽然展现出强大的深度思考能力,但在解决复杂问题时,往往会频繁切换思路,无法深入思考某个方向,导致最终答案错误。研究团队将这种现象称为“思考不足”(Underthinking),并将其比喻为模型的“注意力缺陷多动障碍”。

研究团队通过分析不同难度级别的数学问题,发现模型在难题上的错误答案往往伴随着更多的思路切换和更长的token数量,但准确率并未提升。他们进一步提出了一种“思考不足”评分机制,定量评估模型在错误回答中推理效率的低下程度。

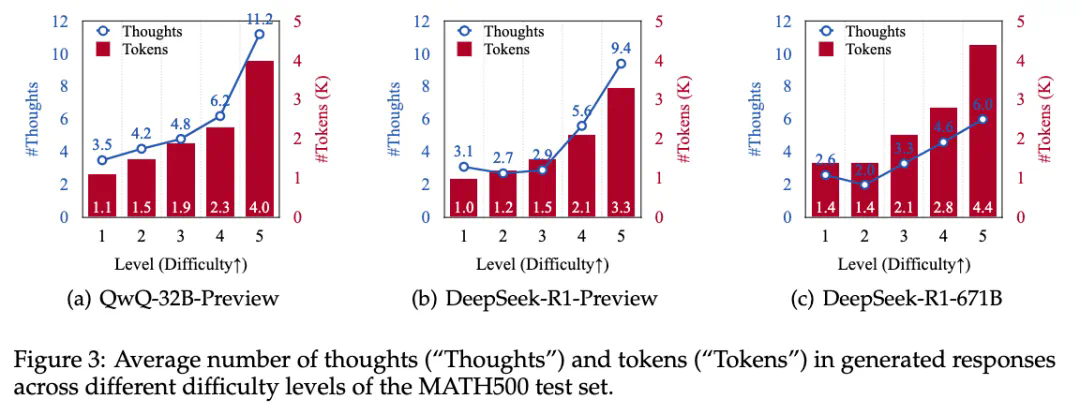
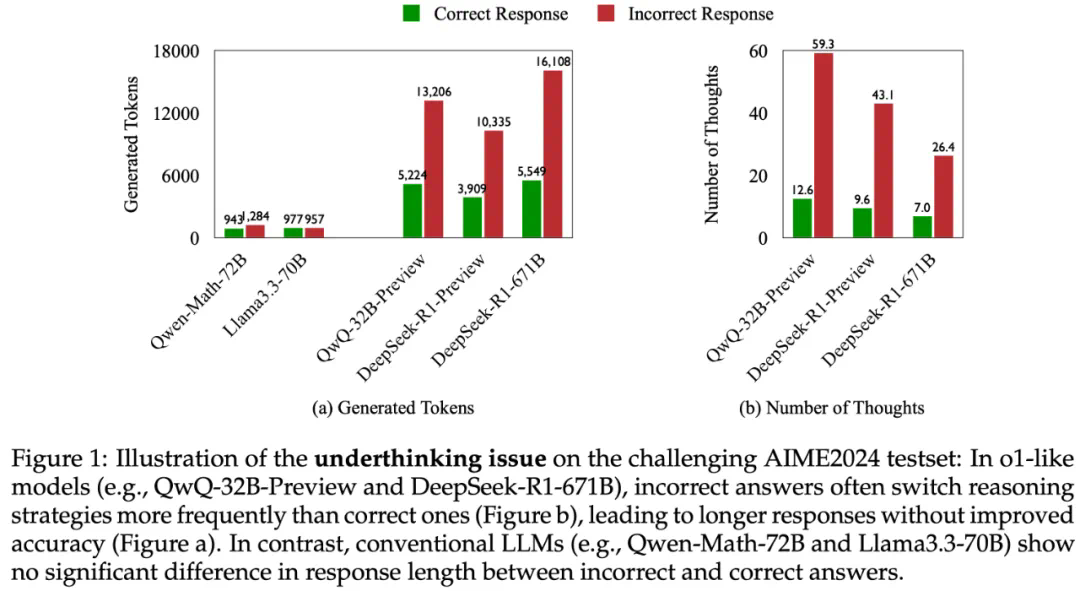

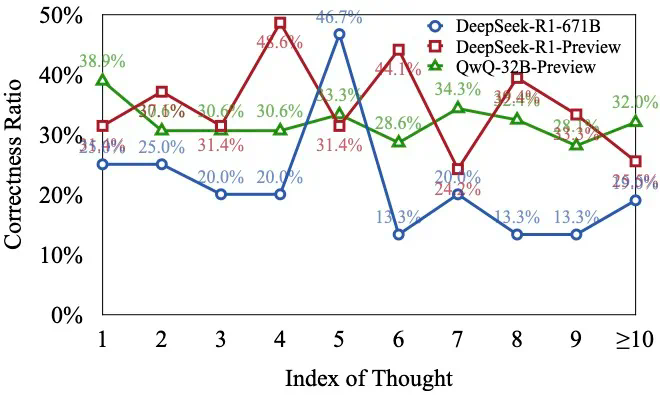
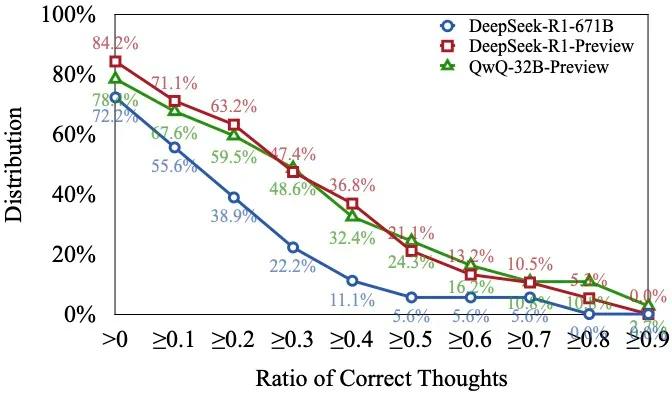
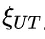

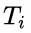
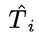
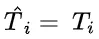
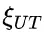
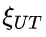
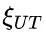
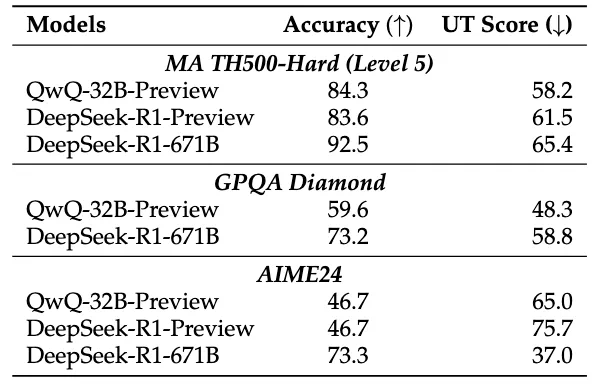

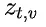




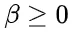
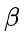
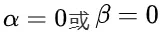
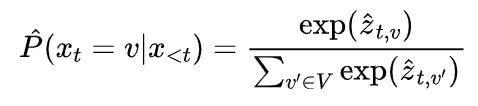
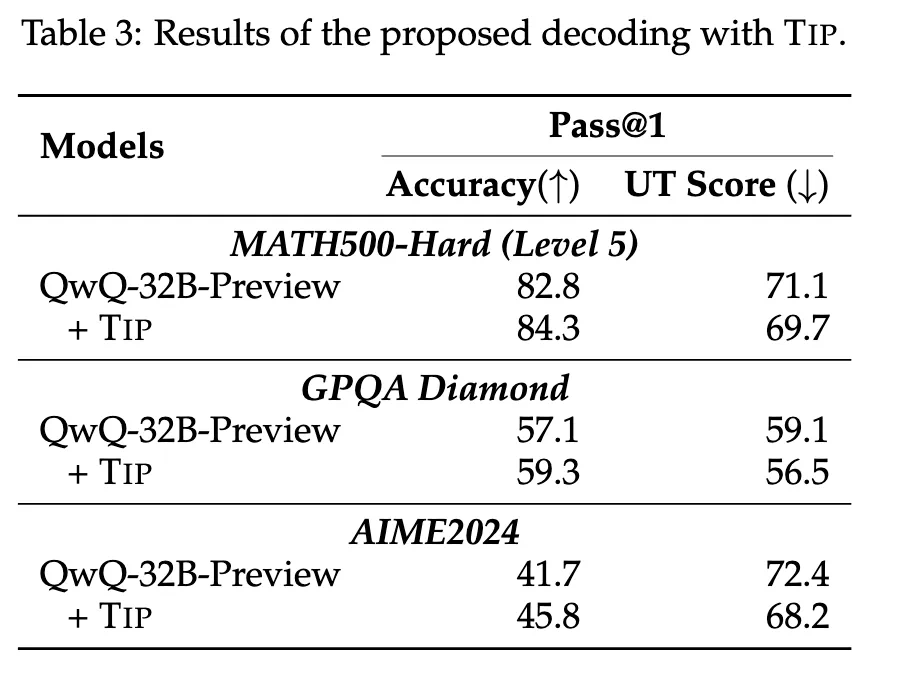
为解决这个问题,研究团队提出了一种名为“思路转换惩罚”(ThoughtswitchingPenalty,TIP)的解码策略,通过惩罚思路切换行为来鼓励模型更深入地思考。实验结果表明,TIP策略能够有效提升模型的准确率并降低“思考不足”现象。这项研究为改进长推理模型提供了新的思路和方法。
以上就是从想太多到想不透?DeepSeek-R1等长推理模型也存在「思考不足」问题的详细内容,更多请关注其它相关文章!