时间:2025-05-19 关注公众号 来源:网络
在科技的璀璨星河中,香港大学携手上海人工智能实验室与华为诺亚方舟实验室,揭开了一场创新革命的序幕。他们孕育出一位名为LiT的数字精灵,一个在平凡与非凡间穿梭的图像创造者。LiT,带着对极简美学的深刻理解,颠覆了传统,用它那革新性的线性注意力机制,轻巧地避开了自注意力机制的重重计算迷宫,犹如一位武林高手,以最简洁的招式,释放出震撼人心的力量。
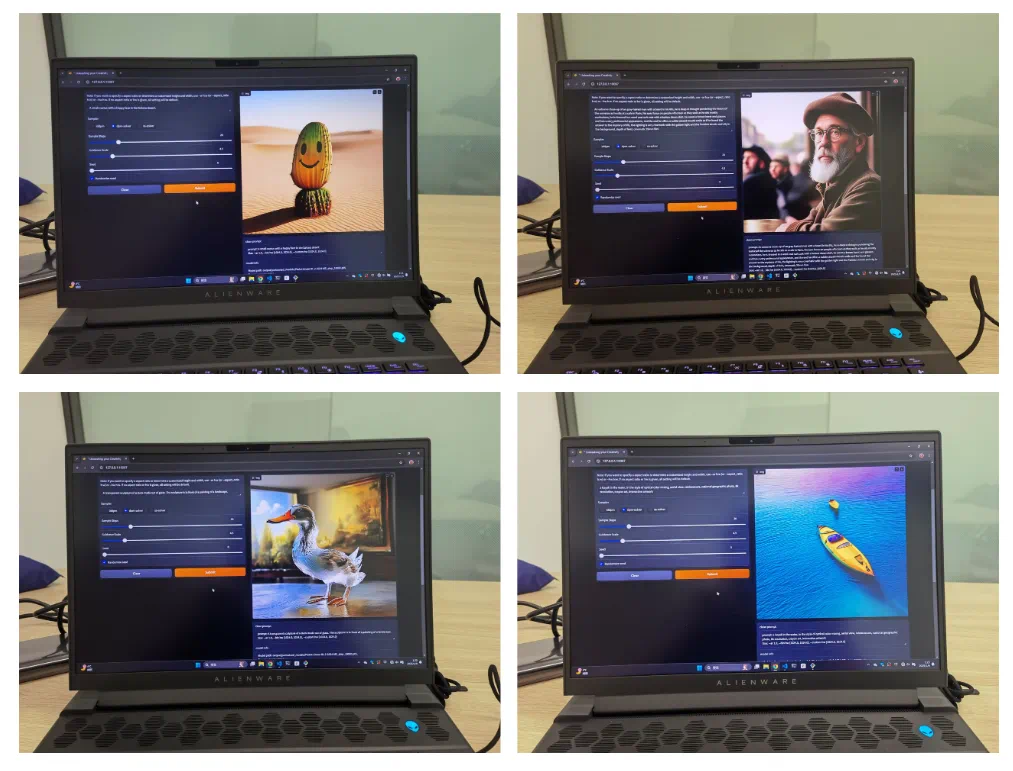
在这片数字的海洋里,LiT不是孤独的旅者,而是携带混合知识蒸馏秘籍的导师,它在DiT模型的智慧基础上,继承而不拘泥,创新而非凡。在寻常的windows笔记本电脑上,LiT展现出了令人瞠目的魔法——离线状态下,它能绘制出1K分辨率的图像,每一笔都细腻如丝,每一色都绚烂如梦,仿佛将现实与幻想的边界模糊,让艺术与技术在指尖交汇。
这不是一场普通的科学实验,而是一次穿越维度的视觉盛宴,一次将高端人工智能技术带入寻常百姓家的壮举。LiT的故事,是关于突破极限,是关于在技术的瀚海中寻找那一抹最亮的光,它告诉我们,即便是在最不起眼的角落,也能绽放出改变世界的光芒。
香港大学与上海人工智能实验室、华为诺亚方舟实验室合作,推出高效扩散模型lit,该模型在架构设计和训练策略上均有创新,实现了在普通windows笔记本电脑上离线生成1k分辨率高清图像。
LiT的核心突破:
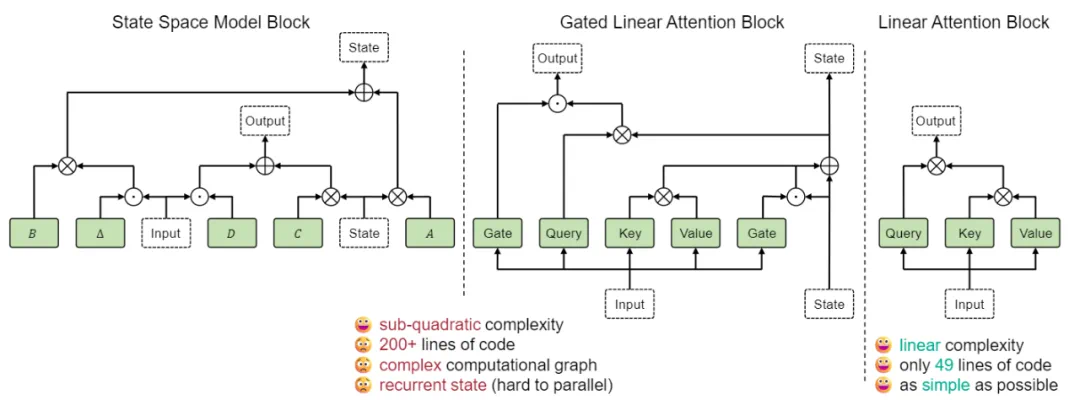
为提升扩散模型效率,LiT采用极简线性注意力机制替代计算成本更高的自注意力机制。线性注意力的优势在于简洁性和高并行化能力,这对于大型模型至关重要。研究团队总结了以下关键经验:
极简线性注意力足够:无需复杂的线性注意力变体,简化版即可满足图像生成需求。 权重继承策略:建议从预训练的DiffusionTransformer模型继承权重,但需排除自注意力模块的权重。 混合知识蒸馏:采用知识蒸馏加速训练,同时蒸馏噪声预测和方差预测结果,以获得更佳效果。性能表现:
LiT在ImageNet基准测试中,仅需DiT模型20%-23%的训练迭代次数,即可达到相当的FID分数。在文本生成图像任务中,LiT-0.6B可在离线状态下,于Windows笔记本电脑上快速生成1K分辨率的逼真图像,展现出强大的端侧部署能力。
论文及项目信息:
论文名称:LiT:DelvingintoaSimplifiedLinearDiffusionTransformerforImageGeneration 论文地址: 项目主页:研究背景:
DiffusionTransformer在文生图领域展现出巨大潜力,但自注意力机制的高计算复杂度限制了其在高分辨率场景和端侧设备的应用。LiT通过线性注意力机制有效解决了这一问题,并通过高效的训练策略进一步降低了训练成本。
(后续内容可根据原文目录,对架构设计、训练方法、实验结果等章节进行类似的改写,保持原意不变,并保留图片格式和位置)
以上就是线性扩散模型LiT来了,用极简线性注意力助力扩散模型AIPC时代端侧部署的详细内容,更多请关注其它相关文章!
上一篇:dot是什么币种