时间:2026-03-12 关注公众号 来源:网络
探索OpenClaw的奥秘,这是一场技术与智慧的碰撞,深潜于人工智能的浩瀚宇宙。在部署的舞台上,日志不仅是文字的堆砌,它们是智能生命——OpenClaw启动之旅的脉络图。当“Model loaded successfully”犹如晨星般闪耀,标志着Qwen3-4B-Instruct-2507这一思维巨匠的觉醒,其智识在GPU的神经网络中铺展,预示着力量与知识的完美融合。
vLLM引擎,心脏般的存在,一旦“initialized”,便织就了逻辑与速度的网,平行世界的采样在它的调度下舞蹈。服务器的呼吸,透过“Server started on port 8000”的宣言,清晰而坚定,每一比特的数据交流都是智慧的触碰。
然而,挑战如影随形,“CUDA out of memory”是极限的呼唤,提醒着资源的珍贵与优化的艺术。在这场与技术边界无尽的对话中,每一道难题都是通往更深层次理解的桥梁,激发着我们对高效利用与扩展计算边界的不懈追求。
OpenClaw,不仅是一款工具,它是探索AI未知领域的勇敢探险者,邀请你一同解开智能的谜团,跨越障碍,向着技术的星辰大海,扬帆远航。在每一个日志的字里行间,跳动的是创新的火花,照亮未来科技的无限可能。

如果您在部署OpenClaw时遇到服务无法启动、响应异常或功能失灵等问题,日志文件是定位根源的第一手依据。其中,/root/workspace/llm.log 是nanobot核心组件的关键运行日志,完整记录模型加载、vLLM引擎初始化、请求处理及资源状态等全过程信息。以下是针对该日志的系统性分析方法:
一、识别日志关键成功标识
正常部署完成的日志中必须包含三项不可缺省的确认信号,缺失任一即表明服务未完全就绪。这些信号是判断部署是否“真正成功”的硬性标准,而非仅凭进程存在与否。
1、查找包含 "Model loaded successfully" 的行,该语句代表Qwen3-4B-Instruct-2507模型权重已从磁盘完整载入GPU显存;
2、确认存在 "vLLM engine initialized" 字样,表示推理引擎底层调度器、KV缓存管理器及并行采样模块均已注册并准备就绪;
3、定位形如 "Server started on port 8000" 的监听声明,端口号需与配置文件中指定值严格一致,且该端口未被其他进程占用。
二、解析高频错误日志条目
当上述成功标识缺失或伴随报错信息出现时,需按错误类型分层排查。每类错误均对应明确的底层原因和可验证的修复路径,避免泛化归因。
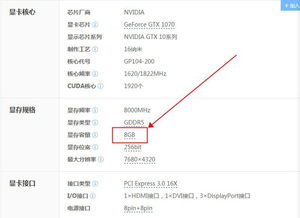
1、若日志中反复出现 "CUDA out of memory" 或 "OOM",说明GPU显存不足以容纳当前batch size下的模型参数与推理中间态,典型触发场景为8GB显存卡运行默认配置;
2、发现 "Loading model weights" 后长时间无后续输出(超5分钟),大概率因网络中断导致模型权重下载不全,此时/root/workspace/models目录下文件大小将明显小于官方公布的sha256校验值;
3、日志起始段含 "Permission denied" 且路径指向 /root/workspace/llm.log 自身,表明当前运行用户对日志文件或其父目录缺少写权限,常见于非root用户误启服务或SELinux策略拦截;
4、出现 "Invalid API key" 提示,说明chainlit前端调用后端API时认证失败,需核对 .env 文件中 OPENCLAW_API_KEY 值是否与模型服务端配置完全一致,注意不可混入空格或换行符。
三、提取性能瓶颈指标
llm.log 不仅用于故障诊断,还内嵌周期性资源监控数据,可用于评估服务健康度与扩容阈值。这些指标以结构化文本形式输出,无需额外工具即可人工提取。
1、定位含 "Loading TIMe" 的行,提取冒号后数值,单位为秒,若持续超过 30s,需检查磁盘I/O延迟或模型文件完整性;
2、搜索 "Inference latency" 字段,其后数值代表单次请求端到端耗时,生产环境应稳定低于 500ms,超出则可能受cpu争抢或GPU利用率过低影响;
3、匹配 "GPU utilization" 行,读取百分比数值,长期低于 30% 表明计算资源闲置,高于 95% 则存在调度阻塞风险;
4、捕获 "GPU memory" 后的占用率,若持续高于 90%,将直接触发OOM错误,必须立即调整并发请求数或启用vLLM的PagedAttention内存优化。
四、验证日志完整性与实时性
日志文件本身的状态直接影响分析结论的可信度。一个被截断、权限异常或未实时刷新的日志,会掩盖真实问题或制造虚假线索。
1、执行 ls -lh /root/workspace/llm.log 查看文件大小,全新部署后正常体积应大于2MB,若长期维持在0字节或数KB,说明服务未实际写入日志;
2、运行 tail -n 20 /root/workspace/llm.log 观察末尾时间戳,若最新条目早于当前系统时间5分钟以上,需检查服务进程是否僵死或日志轮转机制误删主文件;
3、使用 lsof -i :8000 确认监听端口的持有进程PID,再通过 ps -p [PID] -o pid,ppid,cmd 验证该进程是否确为nanobot主程序,排除端口被僵尸进程占用的干扰。
五、交叉比对多源日志定位复合故障
单一llm.log无法覆盖全部故障面,需联动其他日志源进行三角验证。尤其当llm.log显示“成功”但服务仍不可用时,必须启动跨日志溯源流程。
1、检查 /var/log/syslog 中是否存在内核级OOM Killer日志,格式为 "Out of memory: Kill process [pid] ([name]) score [num] or sacrifice child",该记录优先级高于llm.log,一旦出现即证实GPU内存已被强制回收;
2、读取 /root/workspace/chainlit.log(若启用Web界面),重点筛查 "Connection refused" 或 "502 Bad Gateway" 错误,此类报错表明chainlit前端与llm服务间通信链路断裂,而非模型自身故障;
3、执行 journalctl -u nanobot --since "2 hours ago" -n 50 获取systemd服务单元日志,确认服务是否因配置语法错误(如YAML缩进异常)在启动阶段即崩溃退出,此类错误不会写入llm.log。