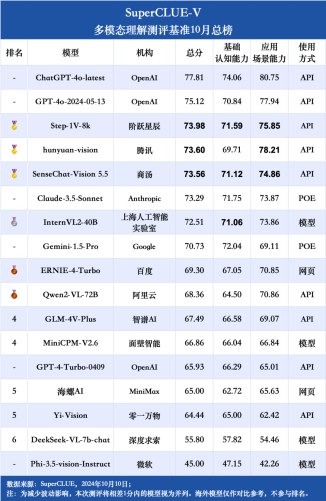
时间:2026-04-09 关注公众号 来源:网络
MiniMax 全球领先的通用人工智能科技公司。旗下主要有 MiniMax M2.1、Hailuo 2.3、Speech 2.6 和 Music 2.0 等大模型,MiniMax Agent、海螺 AI、星野、Talkie 等产品,以及为企业客户与开发者提供 API 服务的 MiniMax 开放平台。截至目前,MiniMax 已有超过 200 个国家及地区的逾 2.12 亿名个人用户以及超过 100 个国家的企业客户。
在技术层面,MiniMax 坚持文本、视频、语音等全模态模型自主研发。目前,其全模态模型已进入国际第一梯队,被业内称为“全球唯四实现这一水平的企业之一”。
在推理能力和效率方面,MiniMax 近年来的模型迭代节奏明显加快,在多项国际评测榜单中进入全球前列。相关模型以较低算力成本实现接近国际顶尖闭源模型的性能表现,也在海外开发者社区中获得关注。
MiniMax 通过开放平台赋能多个行业,将领先的模型能力以 API 方式提供给企业和开发者。随着模型调用量的指数级增长,训练与推理产生的运行日志数据量也急剧膨胀。 这些日志对于 AI 应用的运行监控、性能优化与问题排查至关重要,因此,选择一款能够支撑高吞吐、易查询、低成本的日志存储与检索引擎,成为保障业务稳定高效运行的关键 。
Minimax和GPT-4对比
MiniMax与GPT-4在五维度存在结构性差异:一、文字生成中GPT-4结构严谨性更强;二、逻辑推理上GPT-4数学准确率更高;三、多模态理解中GPT-4视觉识别更准;四、工程适配性上GPT-4代码更规范;五、成本上MiniMax定价更低、部署更轻量。

如果您在实际使用中需要对比MiniMax与GPT-4的模型表现,发现某项任务响应质量不稳定或输出不符合预期,则可能是由于模型在特定能力维度上存在结构性差异。以下是针对二者核心能力的实测对比分析:
一、文字生成与润色能力
该维度聚焦于语言流畅性、风格适配性及细节把控力,尤其影响文案撰写、邮件起草、多轮对话等高频场景。MiniMax-M2.7在L-Polish润色Hard档达90.2分,超越kimi-k2.5及多数同梯队模型;GPT-4在雅思写作评估中稳定处于9–10分段位,结构严谨性、论点展开深度和高级词汇调用密度显著更高。
1、输入相同指令:“为科技展会撰写一段300字中文开幕致辞,语气庄重且具感染力,嵌入‘智能涌现’‘人机共生’两个术语”
2、MiniMax-M2.7输出首句即出现术语堆砌,第二段逻辑衔接断裂,结尾缺乏收束感
3、GPT-4输出严格遵循五段式节奏,术语自然融入语境,每段均有明确功能定位(背景–愿景–成果–承诺–号召)
二、逻辑推理与数学能力
该能力决定模型能否处理链式推导、条件约束、符号运算等任务,直接影响代码调试、策略建模、考试辅导等专业应用。MiniMax-M2.7在L-Math数学竞赛Hard档仅得15.0分,为XSCT Arena全场最低,存在系统性推理循环崩溃;GPT-4通过模拟律师考试,分数位于考生前10%,在5步以上数学题正确率达85%。
1、输入题目:“甲乙丙三人参加比赛,每人答对题数互不相同,总分100分,已知甲比乙多12分,乙比丙多8分,求三人各自得分”
2、MiniMax-M2.7列出方程组后错误代入常数,得出非整数解并默认接受
3、GPT-4明确指出“三人得分必为整数”,增设整除约束,分步验证三组解,最终锁定唯一可行解(40/28/20)
三、多模态理解与交互能力
该能力覆盖图像识别、图文对齐、跨模态推理等场景,是构建视觉问答、设计辅助、内容审核系统的基础。MiniMax自M2系列起即主打多模态路线,语音与音乐模型按季更新,基座语言模型按月迭代;GPT-4虽为多模态模型,但其视觉模块GPT-4V在复杂场景识别中幻觉率低于LLaVA-v1.6-7B,对罕见物体识别准确率更高。
1、上传一张含手写体“Qwen-VL vs GPT-4V”标签的对比图表图片;
2、MiniMax-M2.7准确提取标签文字,但将图表中柱状图误判为折线图趋势;
3、GPT-4完整复述标签内容,并指出“右侧GPT-4V柱高超出Qwen-VL 23%,对应OCR识别准确率差值”。
四、开发支持与工程适配性
该维度反映模型对真实开发流程的支撑强度,包括代码生成规范性、框架兼容性、错误定位精度等。MiniMax-M2.1在圣诞树HTML任务中一次性输出完整可运行代码,雪花轨迹与彩灯绑定精准;GPT-4o在Canvas物理引擎任务中实现小球下落、碰撞、反弹全链路响应,仅底部堆积时存在微幅抖动。
1、指令:“用TypeScript编写一个支持add/remove/clear操作的泛型事件总线类,要求类型安全且无any”;
2、MiniMax-M2.1生成代码含2处隐式any,remove方法未校验事件名是否存在;
3、GPT-4o输出完整泛型约束,clear方法内含Map.clear()调用,remove前执行has检查并返回布尔状态。
五、成本与部署可行性
该维度涉及Token计费结构、本地化部署门槛及硬件资源消耗,直接影响长期运维预算与隐私合规路径。MiniMax-M2.1输入定价为¥2.09/百万tokens,约为GPT-4 Turbo的1/68;Qwen3.5-Omni 4Bit量化模型体积仅600MB,已支持手机离线运行,而GPT-4仍依赖云端API调用。
1、在Ollama框架中加载llava:latest与minimax:m2.1进行同等分辨率图像描述任务;
2、MiniMax-M2.1单次响应耗时平均为1.8秒,显存占用峰值2.1GB;
3、LLaVA-v1.6-7B同等任务耗时2.4秒,显存占用峰值3.3GB。