时间:2025-05-16关注公众号来源:网络
在人工智能的浩瀚宇宙中,有一颗新星正以独特的光芒吸引着研究者的目光——“揭开月影:A3B”,这是基于Moonlight-16B架构深度开发的开源多专家(MoE)模型。此模型的设计灵感源自于月球那未被充分探索的暗面,象征着对未知领域知识的渴望与追求。MoE,即多专家模型,通过集成多个专门处理不同任务的子模型,实现了在大规模数据上的高效学习与推理,这不仅极大地提升了模型的泛化能力,还为资源受限环境下的复杂问题解决提供了新的可能。在这一开创性的工作中,我们不仅仅是在开源一个模型,更是在分享一种探索未知、挑战极限的科研精神。随着A3B的面纱被缓缓揭开,它将如何改变AI界的面貌,让我们共同期待这场技术的月光盛宴。
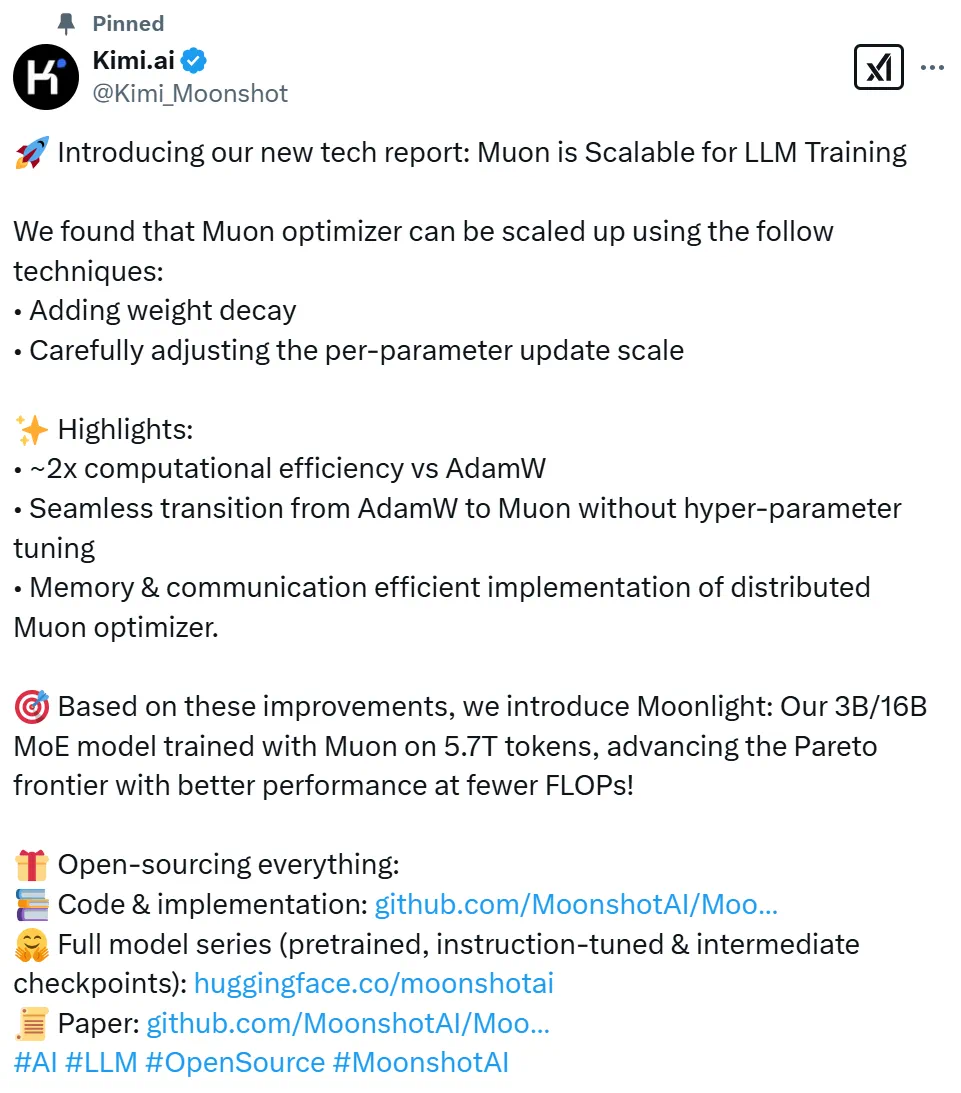
Moonlight-16B-A3B是什么moonlight-16b-a3b是moonshotai推出的新型mixture-of-expert(moe)模型,具有160亿总参数和30亿激活参数。模型使用了优化后的muon优化器进行训练,计算效率是传统adamw的两倍。在性能方面,moonlight在多个基准测试中表现优异,在英语语言理解(mmlu)和代码生成(humaneval)等任务中均超越了其他同类模型。模型的训练数据量达到5.7万亿token,展现了更高的样本效率。
 Moonlight-16B-A3B的主要功能 高效的语言理解和生成:该模型通过优化后的Muon优化器进行训练,能在多种语言任务中表现出色,例如语言理解、文本生成和代码生成。 大规模数据训练:Moonlight-16B-A3B使用了5.7万亿token的数据进行训练,支持高效率的分布式训练。 高效优化器与训练效率:模型使用了改进后的Muon优化器,相比传统的AdamW优化器,计算效率提升约2倍。通过优化权重衰减和参数更新比例,Muon优化器在大规模训练中表现出更高的稳定性和效率。 低计算成本:模型仅需约52%的训练FLOPs即可达到与AdamW训练相当的性能。 低激活参数设计:总参数量为16B,激活参数仅为3B,在保持高性能的同时显著降低了计算资源需求。 Moonlight-16B-A3B的技术原理 Muon优化器的改进:Moonlight-16B-A3B使用了经过优化的Muon优化器。Muon优化器通过矩阵正交化技术(如Newton-Schulz迭代)对模型参数进行优化,显著提升了训练效率。与传统的AdamW优化器相比,Muon的样本效率提升了约2倍,在大规模训练中表现出更高的稳定性和效率。 权重衰减与更新调整:为了提高Muon在大规模模型训练中的表现,开发团队引入权重衰减机制,对每个参数的更新规模进行了调整。使Muon能在无需超参数调整的情况下直接应用于大规模模型训练。 分布式实现:Moonlight-16B-A3B的训练采用了基于ZeRO-1的分布式优化技术。减少了内存开销,降低了通信成本,使模型能在大规模分布式环境中高效训练。 模型架构与训练数据:Moonlight-16B-A3B是一个16B参数的MoE模型,激活参数为3B,使用了5.7万亿个标记进行训练。在保持高性能的同时,显著降低了计算资源需求。 性能优化:通过优化的Muon优化器和高效的分布式训练,Moonlight-16B-A3B在多个基准测试中表现出色,超越了其他同规模模型。 Moonlight-16B-A3B的项目地址 GitHub仓库: HuggingFace模型库: 技术论文: Moonlight-16B-A3B的性能效果 语言理解任务 MMLU(MultilingualLanguageUnderstanding):Moonlight-16B-A3B的性能达到了70.0%,显著优于LLAMA3-3B(54.75%)和Qwen2.5-3B(65.6%)。 BBH(BoolQBenchmark):Moonlight在任务中达到了65.2%,优于其他同类模型。 TriviaQA:Moonlight的表现为66.3%,接近或超越了其他模型。 代码生成任务 HumanEval:Moonlight在代码生成任务中达到了48.1%的性能,优于LLAMA3-3B(28.0%)和Qwen2.5-3B(42.1%)。 MBPP(Mini-BenchmarkforProgramSynthesis):Moonlight的性能为63.8%,显著优于其他模型。 数学推理任务 GSM8K:Moonlight在该任务中的表现为77.4%,接近Qwen2.5-3B的最佳表现(79.1%)。 MATH:Moonlight的性能为45.3%,优于其他同类模型。 CMath:Moonlight达到了81.1%的性能,优于Qwen2.5-3B(80.0%)。 中文任务 C-Eval:Moonlight的性能为77.2%,优于Qwen2.5-3B(75.0%)。 CMMLU:Moonlight的表现为78.2%,优于其他同类模型。 计算效率 训练效率:Moonlight使用的Muon优化器在计算效率上是AdamW的2倍,仅需约52%的训练FLOPs即可达到与AdamW相当的性能。 内存和通信效率:通过改进的分布式实现,Moonlight在大规模训练中表现出更高的内存和通信效率。 Benchmark(Metric) Llama3.2-3B Qwen2.5-3B DSV2-Lite Moonlight ActivatedParam? 2.81B 2.77B 2.24B 2.24B TotalParams? 2.81B 2.77B 15.29B 15.29B TrainingTokens 9T 18T 5.7T 5.7T OpTIMizer AdamW * AdamW Muon English MMLU 54.75 65.6 58.3 70.0 MMLU-pro 25.0 34.6 25.5 42.4 BBH 46.8 56.3 44.1 65.2 TriviaQA? 59.6 51.1 65.1 66.3 Code HumanEval 28.0 42.1 29.9 48.1 MBPP 48.7 57.1 43.2 63.8 Math GSM8K 34.0 79.1 41.1 77.4 MATH 8.5 42.6 17.1 45.3 CMath – 80.0 58.4 81.1 Chinese C-Eval – 75.0 60.3 77.2 CMMLU – 75.0 64.3 78.2 Moonlight-16B-A3B的应用场景 教育和研究:在学术研究中,Moonlight可以帮助研究人员快速理解和分析大量文献。 软件开发:开发者可以用Moonlight自动生成代码片段,提高开发效率。 研究和工程:研究人员和工程师可以用Moonlight解决实际问题中的数学难题。 中文内容创作:在内容创作领域,Moonlight可以帮助创作者生成高质量的中文内容。 大规模模型训练:在需要大规模模型训练的场景中,Moonlight可以显著降低计算资源需求,提高训练效率。
Moonlight-16B-A3B的主要功能 高效的语言理解和生成:该模型通过优化后的Muon优化器进行训练,能在多种语言任务中表现出色,例如语言理解、文本生成和代码生成。 大规模数据训练:Moonlight-16B-A3B使用了5.7万亿token的数据进行训练,支持高效率的分布式训练。 高效优化器与训练效率:模型使用了改进后的Muon优化器,相比传统的AdamW优化器,计算效率提升约2倍。通过优化权重衰减和参数更新比例,Muon优化器在大规模训练中表现出更高的稳定性和效率。 低计算成本:模型仅需约52%的训练FLOPs即可达到与AdamW训练相当的性能。 低激活参数设计:总参数量为16B,激活参数仅为3B,在保持高性能的同时显著降低了计算资源需求。 Moonlight-16B-A3B的技术原理 Muon优化器的改进:Moonlight-16B-A3B使用了经过优化的Muon优化器。Muon优化器通过矩阵正交化技术(如Newton-Schulz迭代)对模型参数进行优化,显著提升了训练效率。与传统的AdamW优化器相比,Muon的样本效率提升了约2倍,在大规模训练中表现出更高的稳定性和效率。 权重衰减与更新调整:为了提高Muon在大规模模型训练中的表现,开发团队引入权重衰减机制,对每个参数的更新规模进行了调整。使Muon能在无需超参数调整的情况下直接应用于大规模模型训练。 分布式实现:Moonlight-16B-A3B的训练采用了基于ZeRO-1的分布式优化技术。减少了内存开销,降低了通信成本,使模型能在大规模分布式环境中高效训练。 模型架构与训练数据:Moonlight-16B-A3B是一个16B参数的MoE模型,激活参数为3B,使用了5.7万亿个标记进行训练。在保持高性能的同时,显著降低了计算资源需求。 性能优化:通过优化的Muon优化器和高效的分布式训练,Moonlight-16B-A3B在多个基准测试中表现出色,超越了其他同规模模型。 Moonlight-16B-A3B的项目地址 GitHub仓库: HuggingFace模型库: 技术论文: Moonlight-16B-A3B的性能效果 语言理解任务 MMLU(MultilingualLanguageUnderstanding):Moonlight-16B-A3B的性能达到了70.0%,显著优于LLAMA3-3B(54.75%)和Qwen2.5-3B(65.6%)。 BBH(BoolQBenchmark):Moonlight在任务中达到了65.2%,优于其他同类模型。 TriviaQA:Moonlight的表现为66.3%,接近或超越了其他模型。 代码生成任务 HumanEval:Moonlight在代码生成任务中达到了48.1%的性能,优于LLAMA3-3B(28.0%)和Qwen2.5-3B(42.1%)。 MBPP(Mini-BenchmarkforProgramSynthesis):Moonlight的性能为63.8%,显著优于其他模型。 数学推理任务 GSM8K:Moonlight在该任务中的表现为77.4%,接近Qwen2.5-3B的最佳表现(79.1%)。 MATH:Moonlight的性能为45.3%,优于其他同类模型。 CMath:Moonlight达到了81.1%的性能,优于Qwen2.5-3B(80.0%)。 中文任务 C-Eval:Moonlight的性能为77.2%,优于Qwen2.5-3B(75.0%)。 CMMLU:Moonlight的表现为78.2%,优于其他同类模型。 计算效率 训练效率:Moonlight使用的Muon优化器在计算效率上是AdamW的2倍,仅需约52%的训练FLOPs即可达到与AdamW相当的性能。 内存和通信效率:通过改进的分布式实现,Moonlight在大规模训练中表现出更高的内存和通信效率。 Benchmark(Metric) Llama3.2-3B Qwen2.5-3B DSV2-Lite Moonlight ActivatedParam? 2.81B 2.77B 2.24B 2.24B TotalParams? 2.81B 2.77B 15.29B 15.29B TrainingTokens 9T 18T 5.7T 5.7T OpTIMizer AdamW * AdamW Muon English MMLU 54.75 65.6 58.3 70.0 MMLU-pro 25.0 34.6 25.5 42.4 BBH 46.8 56.3 44.1 65.2 TriviaQA? 59.6 51.1 65.1 66.3 Code HumanEval 28.0 42.1 29.9 48.1 MBPP 48.7 57.1 43.2 63.8 Math GSM8K 34.0 79.1 41.1 77.4 MATH 8.5 42.6 17.1 45.3 CMath – 80.0 58.4 81.1 Chinese C-Eval – 75.0 60.3 77.2 CMMLU – 75.0 64.3 78.2 Moonlight-16B-A3B的应用场景 教育和研究:在学术研究中,Moonlight可以帮助研究人员快速理解和分析大量文献。 软件开发:开发者可以用Moonlight自动生成代码片段,提高开发效率。 研究和工程:研究人员和工程师可以用Moonlight解决实际问题中的数学难题。 中文内容创作:在内容创作领域,Moonlight可以帮助创作者生成高质量的中文内容。 大规模模型训练:在需要大规模模型训练的场景中,Moonlight可以显著降低计算资源需求,提高训练效率。 以上就是Moonlight-16B-A3B—月之暗面开源的MoE模型的详细内容,更多请关注其它相关文章!