时间:2025-05-16关注公众号来源:网络
在人工智能领域不断突破的今天,算法的高效执行成为了研究与应用的核心议题。为此,摩尔线程推出了一款重量级的工具——MT-TransformerEngine,这是一款精心设计的开源框架,专为加速机器学习中的训练与推理过程而生。它不仅集成了前沿的优化技术,还旨在降低开发者门槛,提升模型部署的效率与性能。通过高度优化的计算内核和灵活的架构设计,MT-TransformerEngine能够显著提升各类Transformer模型的处理速度,无论是复杂的自然语言处理任务,还是图像识别等视觉领域挑战,都能得到有力支持。本篇文章将深入探讨这一框架的关键特性,展示其如何成为推动AI应用快速迭代与高效运行的幕后英雄,以及开发者如何利用这一强大工具解锁更高级的人工智能解决方案。
摩尔线程开源的高效transformer模型训练推理框架:mt-transformerengine
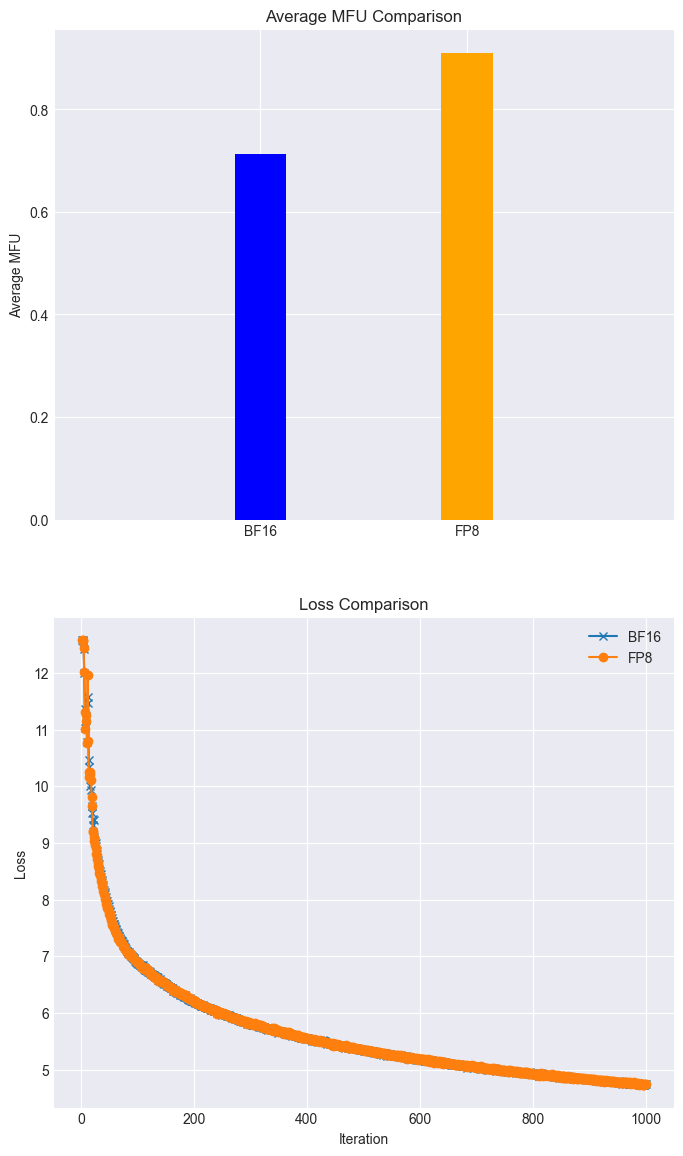
MT-TransformerEngine是摩尔线程针对Transformer模型打造的开源训练与推理优化框架。它充分利用摩尔线程全功能GPU的计算能力,通过算子融合、并行加速等技术手段,显著提升训练效率。框架支持FP8混合精度训练,进一步优化性能和稳定性。配合MT-MegatronLM,MT-TransformerEngine可实现高效的混合并行训练,适用于BERT、GPT等大型模型。

核心功能:
高效训练加速:通过算子融合减少内存访问和计算开销,并支持数据并行、模型并行和流水线并行,最大化GPU集群的计算潜力。 推理优化:针对Transformer模型推理阶段进行优化,降低延迟,提升吞吐量,并优化内存管理。 生态工具集成:与MT-MegatronLM、MT-DualPipe协同工作,并支持Torch-MUSA深度学习框架和MUSA软件栈。 多模态模型支持:可用于训练包含文本、图像等多种模态数据的复杂模型。 通信优化:优化通信策略,降低GPU间通信延迟。技术原理:
算子融合:融合归一化层、QKV、自注意力计算和残差连接等操作,减少访存次数和CUDAKernel启动耗时。 并行加速:支持数据并行、张量并行和流水线并行,并通过MT-DualPipe和DeepEP技术降低“流水线气泡”。 FP8混合精度训练:利用GPU原生FP8计算能力加速训练,同时确保数值稳定性。 高性能算子库:集成muDNN高性能算子库。项目地址:
GitHub仓库:应用场景:
大规模语言模型训练:高效训练数十亿甚至数千亿参数的GPT、BERT、T5等模型。 多模态模型训练:处理包含文本、图像、视频等多种模态的数据。 实时推理:在自然语言处理、图像识别等需要低延迟的场景中提升推理速度。以上就是MT-TransformerEngine—摩尔线程开源的高效训练与推理优化框架的详细内容,更多请关注其它相关文章!