时间:2025-05-19 关注公众号 来源:网络
在科技的最前沿,一场关于智慧的竞赛悄然展开。摩尔线程,这个承载着国产GPU梦想的名字,揭开了一段关于人工智能的新篇章。他们不只挑战极限,更将梦想开源,释放了MT-MegatronLM与MT-TransformerEngine两大神器,犹如古老传说中的秘宝,为每一个追求智慧之心解锁神秘力量。
在这片数字的海洋,模型如巨浪般翻涌,而摩尔线程的GPU则如同深海之舟,驾驭着FP8混合精度的风暴,穿梭于密集计算的迷雾,探索多模态知识的未知领域。MT-MegatronLM,它像是智慧的导师,引导模型们在混合并行的舞蹈中达到效率与稳定的完美平衡;而MT-TransformerEngine,则是加速的引擎,挖掘GPU潜能,让每一次思考都如同闪电般迅捷。
这不仅仅是一场技术的革命,更是国产创新力量的觉醒。在算法与硬件的交响曲中,异常处理机制如守护者般确保每一次探索的安全,让即便是最浩大的知识海洋探险,也能从风浪中安然归来。这是一段关于创新、勇气与智慧的故事,邀请每一个梦想改变世界的你,共同书写国产AI新篇章。
近日,摩尔线程正式开源mt-megatronlm与mt-transformerengine两大ai框架。通过深度融合fp8混合训练策略和高性能算子库,这两大框架在国产全功能gpu上实现了高效的混合并行训练和推理,显著提升了训练效率与稳定性。摩尔线程是国内率先原生支持fp8计算精度的国产gpu企业,此次开源不仅为ai训练和推理提供了全新的国产化解决方案,更对推动国产gpu在ai大模型领域的应用具有重要意义。
▼?MT-MegatronLM开源地址:
▼?MT-TransformerEngine开源地址:
框架介绍
MT-MegatronLM是面向全功能GPU的开源混合并行训练框架,支持dense模型、多模态模型及MoE(混合专家)模型的高效训练。该框架利用全功能GPU支持FP8混合精度策略、高性能算子库muDNN与集合通信库MCCL,可以显著提升国产全功能GPU集群的算力利用率。
MT-TransformerEngine主要用于Transformer模型的高效训练与推理优化,通过算子融合、并行加速策略等技术,充分释放摩尔线程全功能GPU高密度计算的潜力和memorybound算子的效率。
技术突破与优势
两大框架的技术突破集中体现在硬件适配与算法创新的深度协同:
▽?混合并行训练:支持Dense、多模态及MoE模型的混合并行训练,可灵活应对不同模型架构的复杂运算场景;
▽?FP8混合训练策略:结合摩尔线程GPU原生支持的FP8混合精度训练策略,能够有效提升训练效率;
▽?高性能算子库:通过高性能算子库muDNN与通信库MCCL的深度集成,系统性优化了计算密集型任务与多卡协同的通信开销;同时结合摩尔线程开源Simumax库,可自动进行并行策略搜索,并针对不同模型和加速环境spec最大化并行训练性能;
▽?异常训练处理:框架内置的rewind异常恢复机制,可自动回滚至最近稳定节点继续训练,大幅提升大规模训练的稳定性;
▽?完整的兼容性:两个框架兼容GPU主流生态,既保障了现有生态的平滑迁移,也为开发者构建自有的AI技术栈提供了底层支撑。
▼?摩尔线程Simumax开源地址:
实际应用效果
在实际应用中,这两个框架的充分结合已经取得了显著的成果。这些成果不仅验证了框架的技术成熟度,也为国产GPU生态的规模化应用奠定了坚实基础。
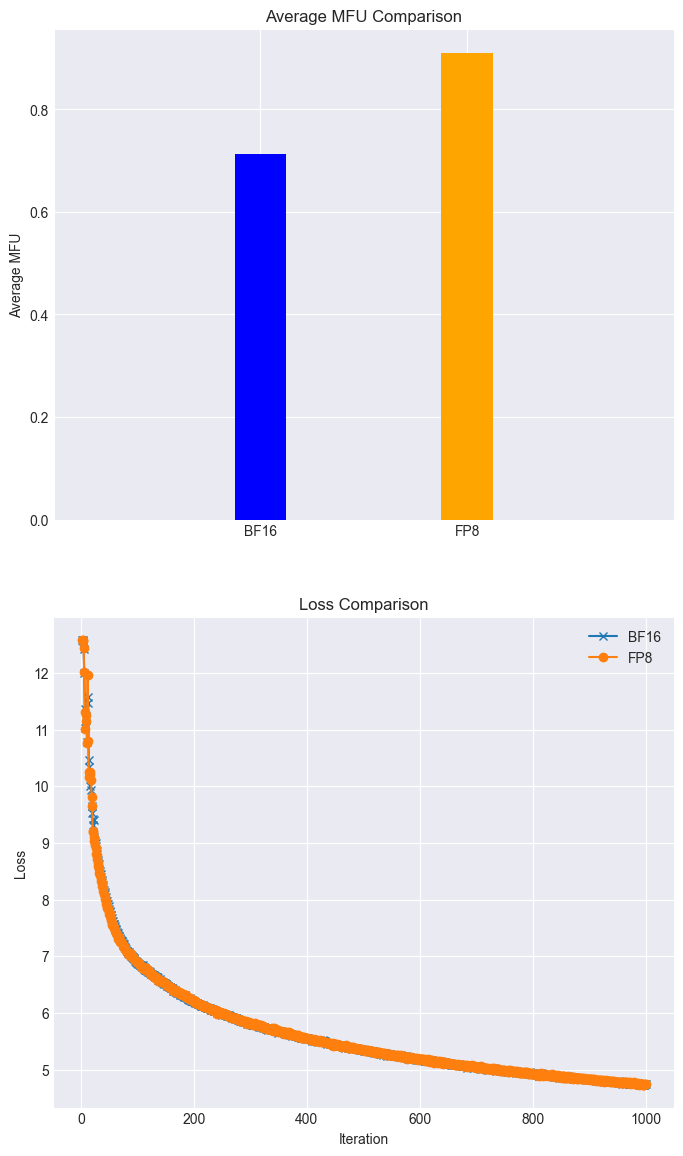
▽?高效训练:在全功能GPU集群上,Llama38B模型的训练任务,可以利用FP8在loss几乎无损的情况下MFU达到90%以上;(如下图所示)
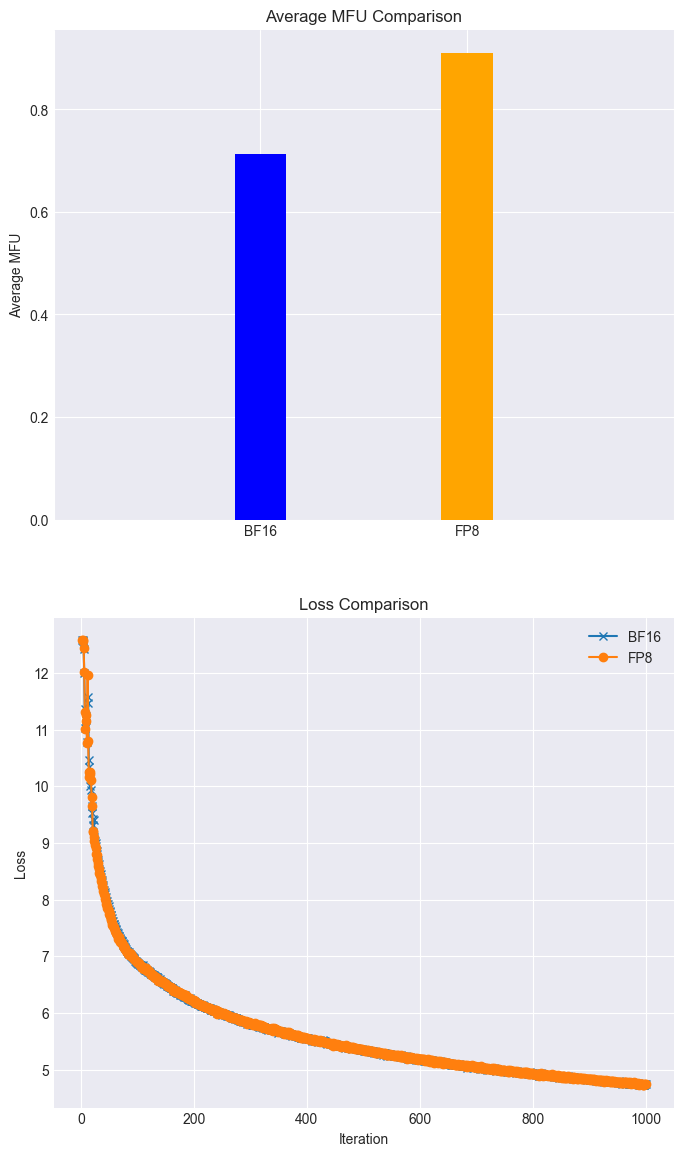
图注:利用摩尔线程FP8混合精度加速技术在loss无损的情况下得到28%的加速
▽?复现DeepSeek满血版训练:摩尔线程已深度集成并开源对DeepSeek并行算法DualPipe的高效支持,MT-DualPipe可以完整接入MT-Megatron框架和MT-TransformerEngine框架,成功实现DeepSeekV3训练流程的完整复现,支持MLA、MTP及多种专家平衡策略;
▽?性能大幅优化:通过多种Transformer算子融合技术,显著提升了内存带宽利用率,有效缓解memorybound瓶颈,进一步释放国产GPU的硬件潜力。
持续优化与生态共建
为加速国产GPU生态发展与建设,摩尔线程将持续优化MT-MegatronLM与MT-TransformerEngine框架,并引入一系列创新功能:
▽?DualPipe/ZeroBubble并行策略:进一步降低气泡率,提升并行训练效率;
▽?多种FP8优化策略:独创的FP8优化策略,提高训练的性能和稳定性;
▽?异步checkpoint策略:提高训练过程中的容错能力和效率;
▽?优化后的重计算策略:减少计算和显存开销,提高训练速度;
▽?容错训练策略:独创的容错训练算法,增强训练过程中的容错能力;
▽?集成摩尔线程FlashMLA和DeepGemm库:进一步释放摩尔线程GPU的算力和FP8计算能力,提升计算性能和效率。
摩尔线程始终致力于推动开源生态的发展,通过技术开放与生态共建,加速国产全功能GPU在AI计算领域的规模化应用,为更多用户提供更智能、高效的解决方案。
以上就是开源MT-MegatronLM和MT-TransformerEngine|摩尔线程GPU原生FP8计算助力AI训练的详细内容,更多请关注其它相关文章!